はじめに
こんにちは。プラットフォームエンジニアリングチームに所属している徳富(@yannKazu1)です。
先日、本番環境でドキュメントの大規模更新を行った際にCPUが100%に張り付く事象が発生しました。検証環境で同じ更新処理を試しても再現せず、原因がわからない。そこで「そもそも自分、Elasticsearchの中で何が起きてるかちゃんと理解してないな」と気づき、インデキシングから検索までの仕組みを一から整理してみました。
同じように「なんでこうなるの?」と悩んでいる方の助けになれば嬉しいです。
前提知識
本記事では、Shard内部の動作にフォーカスして説明していきます。「そもそもShardって?Segmentって?」という方は、メルカリさんのこちらの記事がとてもわかりやすいので、先に読んでおくことをおすすめします。
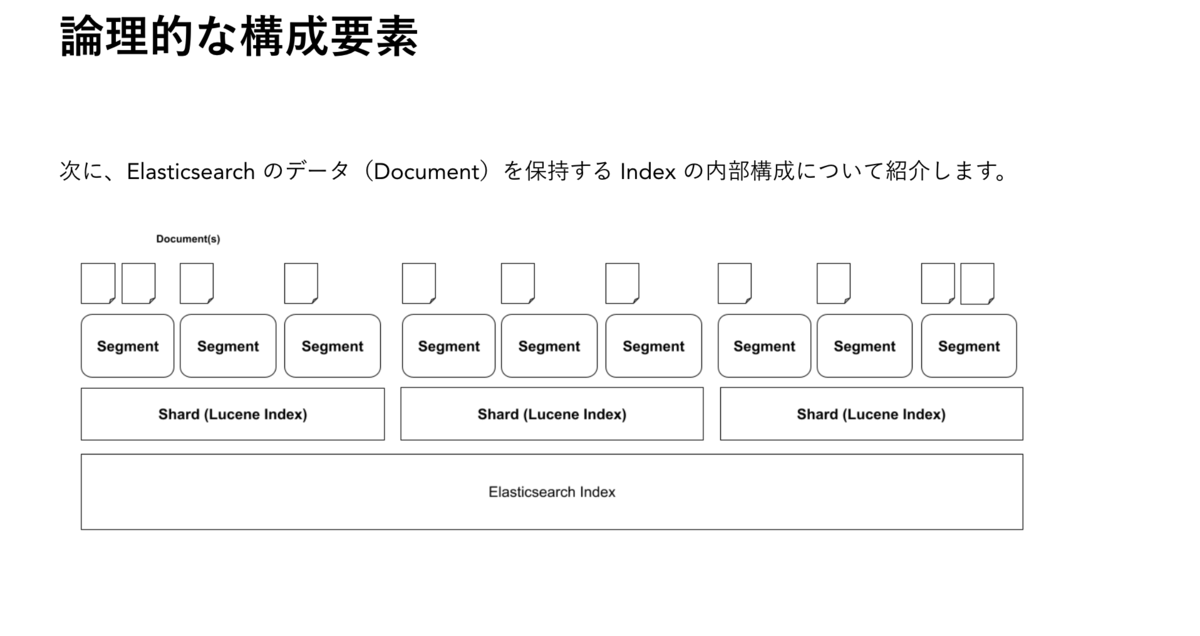
全体の流れ
まず、大枠の流れを押さえておきます。
- インデキシング開始 — ドキュメントがメモリバッファに蓄積される
- Refresh — メモリバッファの内容からセグメントが作られ、検索可能になる
- 検索 — すべてのセグメントを対象に検索が実行される
- セグメントマージ — 小さなセグメントが統合され、削除済みデータも物理削除される
シンプルに書くとこれだけなんですが、それぞれの段階で「何が起きているのか」「どんな時に負荷が上がるのか」を知っておくと、トラブル時の原因切り分けがしやすくなります。
では、各ステップを詳しく見ていきましょう。
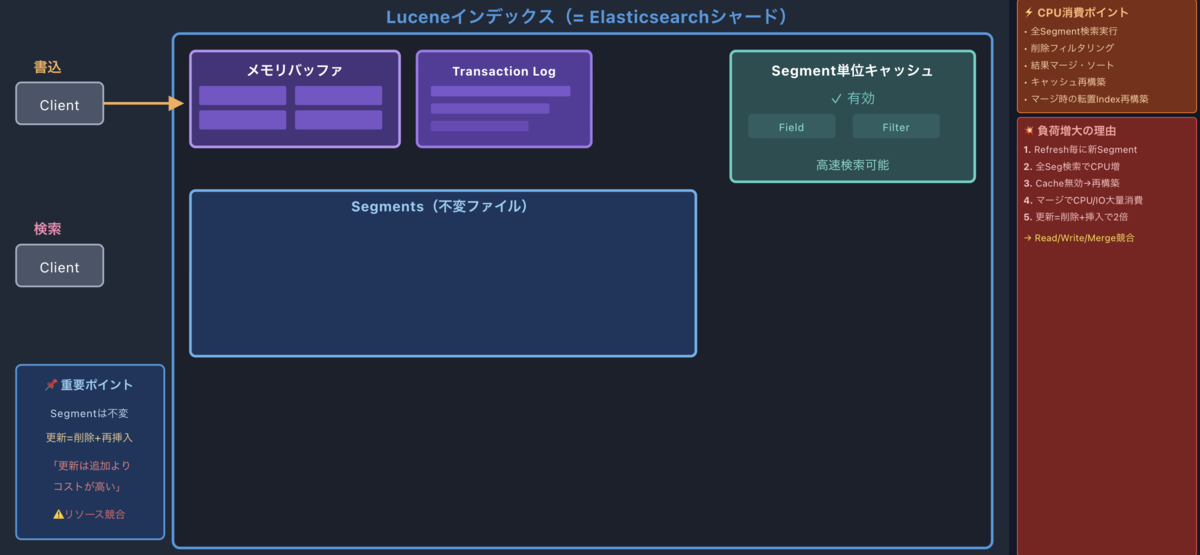
1. インデキシング開始
ドキュメントがインデキシングされると、まずメモリバッファに蓄積されます。同時に、各シャードのTransaction Log(translog)にも操作が記録されます。
Lucene commitは変更のたびに実行するとコストが高すぎるため、その役割をtranslogが担います。万が一プロセスの終了やハードウェア障害が発生しても、translogから操作を再生することでデータを復旧できます。
なお、デフォルト設定(index.translog.durability: request)では、各リクエストごとにtranslogへのfsyncが発生するため、ディスクI/Oが完全にゼロというわけではありません。
 参考ドキュメント:
参考ドキュメント:
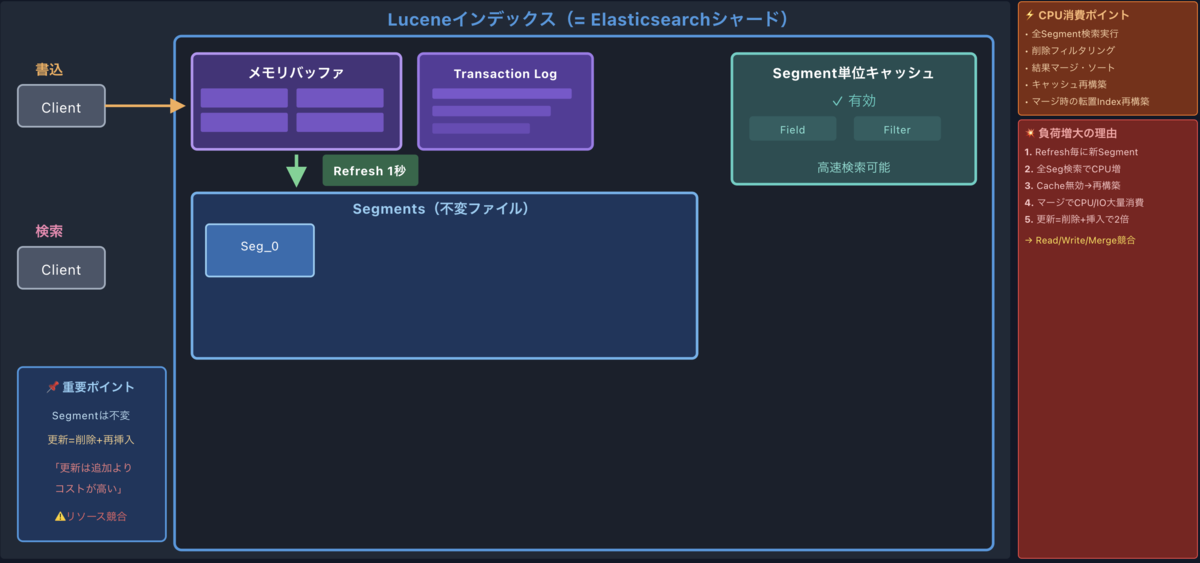
2. Refreshによるセグメント生成
デフォルトでは1秒ごとにRefresh処理が走ります。この処理で、メモリバッファの内容がファイルシステムキャッシュに書き込まれ、immutable(不変)なセグメントが新たに作られます。ここで初めて、そのデータが検索可能になります。
RefreshとFlush、何が違うの?
ここで似た名前の処理が出てくるので、先に整理しておきます。この2つ、最初は「同じようなもの?」と思っていたんですが、実は全く別の操作です。
| 操作 | やっていること | 重さ | 目的 |
|---|---|---|---|
| Refresh | メモリバッファ → メモリ内セグメント作成(ファイルシステムキャッシュ経由) | 軽め | 検索できるようにする |
| Flush | Lucene commit + translogクリア(ディスクに永続化) | 重い | データを永続化する |
重要なのは、検索可能にするのはRefreshだけということです。Flushは永続化のための処理であり、検索可能性には影響しません。検索はメモリ内のセグメントに対して行われるため、Refreshでセグメントが作られて初めて検索できるようになります。
Flushは、translogが一定サイズに達した時や、一定時間が経過した時に発生します。
Search Idleルール
ここで重要なルールがあります。自動Refreshは、過去30秒以内に検索リクエストがあったインデックスだけが対象です(厳密にはシャード単位で管理されます)。つまり、検索トラフィックがあるシャードには定期的なRefresh(デフォルト1秒ごと)が走りますが、検索されていないシャードはバックグラウンドRefreshがスキップされ、リソースが節約される仕組みになっています。これはバルクインデックス時のパフォーマンス最適化を目的とした機能です。
「Refreshがスキップされている間に追加されたデータはどうなるのか」と疑問に思われるかもしれませんが、心配は不要です。アイドル状態のシャードに検索リクエストが来ると、その検索操作の一部としてRefreshがトリガーされ、完了してから検索結果が返されます。つまり、データ自体は問題なく検索できます。ただし、アイドル状態からの最初の検索はRefresh完了を待つ分、レスポンスが遅くなる可能性がある点には注意が必要です。
とはいえ、本番環境と検証環境では動きが変わってくる可能性がある点がポイントです。本番では常にユーザーが検索しているので定期Refreshが走ります。しかし検証環境では誰も検索していない場合、シャードがアイドル状態になり、検索時に初めてRefreshが走ります。同じ更新処理でも、裏側で起きていることがまったく異なる場合があります。
Refresh間隔は調整できます
index.refresh_interval で設定可能です。大量データを投入する時は、この値を大きくしておくとセグメント数を減らすことができます。なお、アイドル判定の時間は index.search.idle.after(デフォルト30秒)で変更できます。
PUT /my-index/_settings { "index": { "refresh_interval": "30s" } }
参考ドキュメント:
- Near real-time search | Elastic Docs - Refreshの仕組み、ファイルシステムキャッシュ経由でのセグメント生成
- Refresh API | Elasticsearch Guide - Refresh APIの詳細、30秒ルール
- Translog settings | Elastic Docs - FlushとTranslogの関係、Lucene commitの説明
- General index settings | Elastic Docs -
index.search.idle.after設定、Search Idle機能の詳細
短期間に大量更新すると何が起きるか
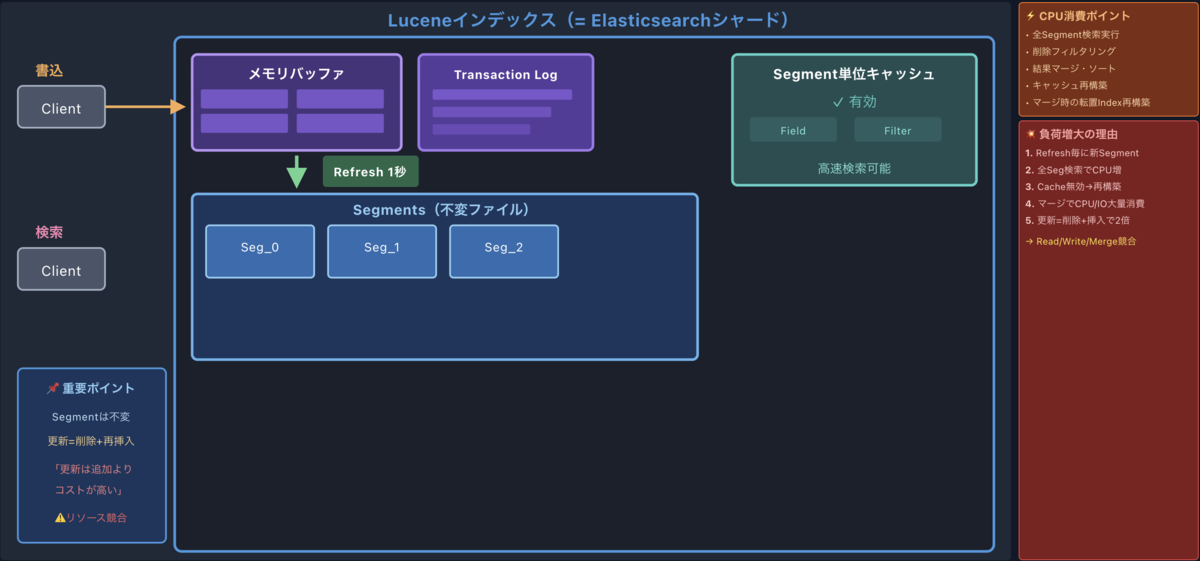
さて、ここからが本題です。短期間に大量の更新が発生すると、Refreshのたびに小さなセグメントがどんどん作られていきます。
セグメントはimmutableなので、「既存のセグメントにちょっと追加」ということができないんです。更新のたびに新しいセグメントを作るしかない。結果として、細かいセグメントが山のように溜まっていきます。
これが引き起こす問題
- セグメントが増えると検索が遅くなる
- ファイルディスクリプタをたくさん消費する
- 後で説明するマージ処理の負荷が大きくなる
対策
大量にインデックスする時は refresh_interval を -1(無効)にしておいて、終わったら手動でRefreshする。これだけでだいぶ違います。
参考ドキュメント:
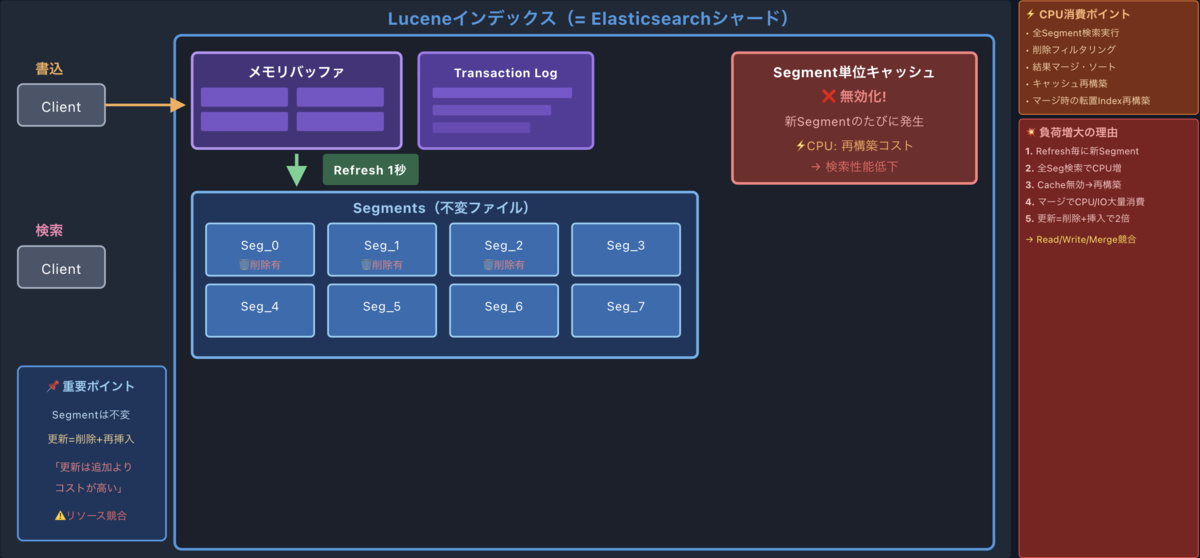
削除処理の仕組み
ドキュメントを削除する時、実際にデータを消しているわけではありません。セグメントがimmutableである以上、「この部分だけ消す」ができないんです。
じゃあどうするかというと、削除フラグ(tombstone)を付けて「削除済み」とマークするだけ。いわゆる論理削除ですね。
実際の流れ
- 削除リクエストが来る
- 対象ドキュメントに削除フラグを付ける
- 検索時はフラグ付きのドキュメントを結果から除外する
- 後でセグメントマージが走った時に、やっと物理的に削除される
つまり、削除したつもりでもマージが完了するまでディスク容量は減らないんです。「削除したのに容量減らないな...」と思ったことがある方、これが原因かもしれません。
参考ドキュメント:
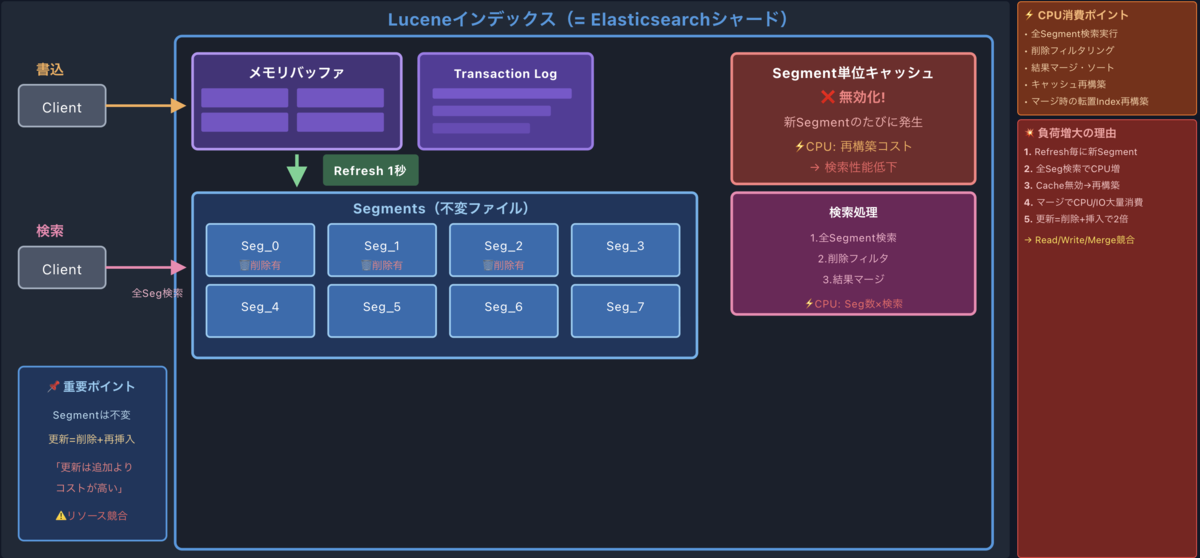
3. 検索時に何が起きているか
検索処理では、すべてのセグメントに対して検索が実行されます。各セグメントの結果をマージして、最終的な検索結果ができあがります。
ここで「セグメントが増えると検索が遅くなる」理由がわかりますよね。検索対象が増えれば増えるほど、当然時間がかかります。
キャッシュの話も重要です
Elasticsearchには主に2種類のキャッシュがあるんですが、どちらもセグメントの変更に影響を受けます。
| キャッシュ | 単位 | いつ無効化される? |
|---|---|---|
| Node query cache | セグメント単位 | セグメントがマージされた時 |
| Shard request cache | シャード単位 | シャードがリフレッシュされた時 |
新しいセグメントにはまだキャッシュがないので、最初のクエリは必ずキャッシュミスになります。しかもマージが走るとせっかく溜めたキャッシュも消えてしまう。
セグメントが頻繁に作られたりマージされたりする環境では、キャッシュがなかなか効かなくなります。
参考ドキュメント:
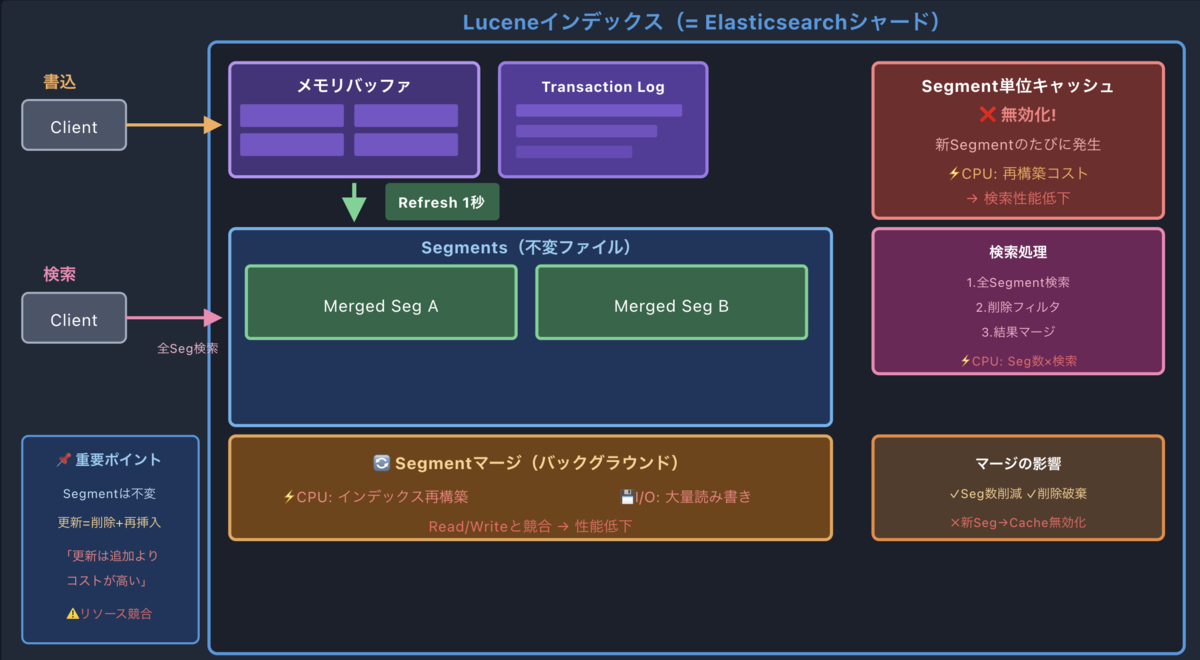
4. セグメントマージ — 重い処理
バックグラウンドで定期的にセグメントのマージ処理が走ります。小さなセグメントをまとめて大きなセグメントにする処理です。この際、転置インデックスの再構築が行われるため、CPUとI/Oを大量に消費します。
マージがもたらすメリット
- 細かいセグメントが大きなセグメントに統合されます
- 削除フラグ付きのドキュメントが物理削除されます
- セグメント数が減るため、検索が高速化します
ただし、マージ中は重い
マージ自体はとても重い処理です。マージが走っている間は、検索もインデキシングも影響を受けます。
ElasticsearchにはAuto-throttling(自動スロットリング)という仕組みがあり、マージがインデキシングに追いつけなくなると、インデキシング自体にブレーキがかかります。これは「セグメント爆発」を防ぐための安全装置です。
セグメントマージがどんな感じで進むのか、視覚的に理解したい方はこちらの記事がおすすめです。
参考ドキュメント:
まとめ
長くなりましたが、ここまで読んでいただきありがとうございます。
今回学んだことで特に大事だなと思ったのは、この3つです。
- セグメントはimmutable — 更新・削除のたびに新しいセグメントができる
- Refreshの30秒ルール — 検索がないシャードはRefreshがスキップされる
- マージは重い — CPU・I/Oを大量に使い、キャッシュも無効化される
本番環境で「なんか重いな」と思った時は、セグメントの状態やマージの発生状況も見てみてください。きっと何かヒントが見つかるはずです。
もし同じような問題で悩んでいる方がいたら、この記事が少しでも参考になれば嬉しいです。
ちなみに、今回の調査をきっかけに、チームメンバーがElasticsearchの詳細な状況を収集できる仕組みを整えてくれました。実際のデータをもとにした分析や考察、情報収集するための観点や方法については、そのメンバーが続編で紹介してくれるかもしれません。お楽しみに!