
他部署の機密データ、クラウドAI使えない問題――OpenAIのgpt-ossより、Qwen3-nextが特許の実務で役立った話

はじめに
「この特許案、技術的に評価してもらえる?まだ出願前だから、絶対に社外秘で」
事業会社でDXを推進していると、こういう依頼が頻繁に来ます。
法務部からの契約書レビュー依頼
営業部からの提案資料の添削依頼
研究開発部からの特許評価依頼
人事部からの社内規程の整合性チェック
どれも「機密情報」です。クラウドのAIサービスには、上げられません。
でも、専門外の内容を、自分だけで判断するのは不安です。そこで私はローカルLLMを使ってみました。
選んだのは、OpenAI社のgpt-ossと、Alibaba製のQwen3-next。
すると、意外な結果になりました。知名度の高いOpenAI社のgpt-ossより、Qwen3-nextの方が「実務的価値」で圧倒的に役立ったのです。
この記事では、その理由と、事業会社のDX推進における「機密データをどう処理するか」の解決策を紹介します。
事業会社のDX、最大の壁は「機密データ」
ChatGPTに投げられない現実
「ChatGPTに聞けば一発なのに…」
そう思う場面は、1日に何度もあります。でも、使えません。
理由は明確です:

ChatGPTやClaude、Geminiなどのクラウドサービスは、データが外部サーバーを経由するという事実から、多くの場合で制約があります。
クラウドAIが必ずしもNGというわけではありませんが、以下の理由で使えないケースがあります:
NDAの内容次第:「第三者への開示禁止」条項がある場合、クラウドAIへの入力は契約違反のリスク
社内規程・部署のルール:情報セキュリティポリシーで外部サービスへのデータ送信が制限されている場合
個人情報保護法:本人の同意なく個人データをAIに入力すると第三者提供とみなされる可能性(個人情報保護委員会 2025年1月見解)
今回の私のケースでは、出願前の特許案件という性質上、クラウドAIは使えませんでした。 各社の判断は異なりますので、法務部・情報セキュリティ部門への確認をお勧めします。
DX推進の矛盾
DX社員として、私の役割は:
業務効率化:AIを使って生産性を上げる
新技術の導入:最新のツールを社内に展開する
デジタル変革:古い業務フローをアップデートする
でも、肝心の機密データでAIが使えないのです。
これは矛盾です。DXを推進するはずが、最も効果的な場面でツールが使えない。
ローカルLLMという選択肢
30万円のPCで、社内で完結
そこで私が選んだのがローカルLLMです。
データは外部に一切送信されない(機密情報も安全)
社内ネットワーク内で完結(情報セキュリティ部門も承認)
月額課金なし(経理処理も楽)
実行環境:
PC: Ryzen AI Max+ 395搭載機(約30万円)
ツール: OpenWebUI、LM Studio
モデル: gpt-oss、Qwen3-next(いずれもローカルで動作)
モデルの選定理由は、MoE(Mixture of Experts)型で、30万円クラスのPCでも実用的に動くためです。
2つのモデルを試した
今回、以下の2つのモデルで比較しました:

正直、OpenAI社のgpt-ossの方が優れているだろうと思っていました。知名度も実績もありますから。
実験:他部署からの特許評価依頼
シチュエーション
ある日、研究開発部から依頼がありました。
「この特許案、出願する価値があるか評価してほしい。まだ出願前だから、社外秘で頼む」
内容は、製造業に機械学習を応用したもの(詳細は企業への配慮から伏せます)。
私もある程度特許は見ていますが、この案件は専門外の技術領域です。自分の見立てを確認する意味でも、ローカルLLMの意見を聞いてみることにしました。
もちろん、特許戦略は各社次第です。同じ技術でも、ポートフォリオ戦略や競合状況によって判断は変わります。ただ、DX推進の立場として、意思決定の材料を迅速に揃えることが重要です。
2つのモデルで評価させた
同じプロンプトを、gpt-ossとQwen3-nextの両方に投げました。
今回の事例では、実在の出願済みの特許を用いました。
プロンプト:
「次のような特許を書こうと思っている。これは、実効性や出願のメリットがありますか。忖度なしで客観的に評価して。」
--- 以下、1万5千文字の特許の請求項と詳細をコピペ
どちらも詳細な評価を返してきました。
しかし、決定的な違いがありました。
結果:2つのモデルの回答の違い
Qwen3-next:最初に結論、次に行動提案
Qwen3-nextは、冒頭でいきなり結論を提示しました。
冒頭の評価:
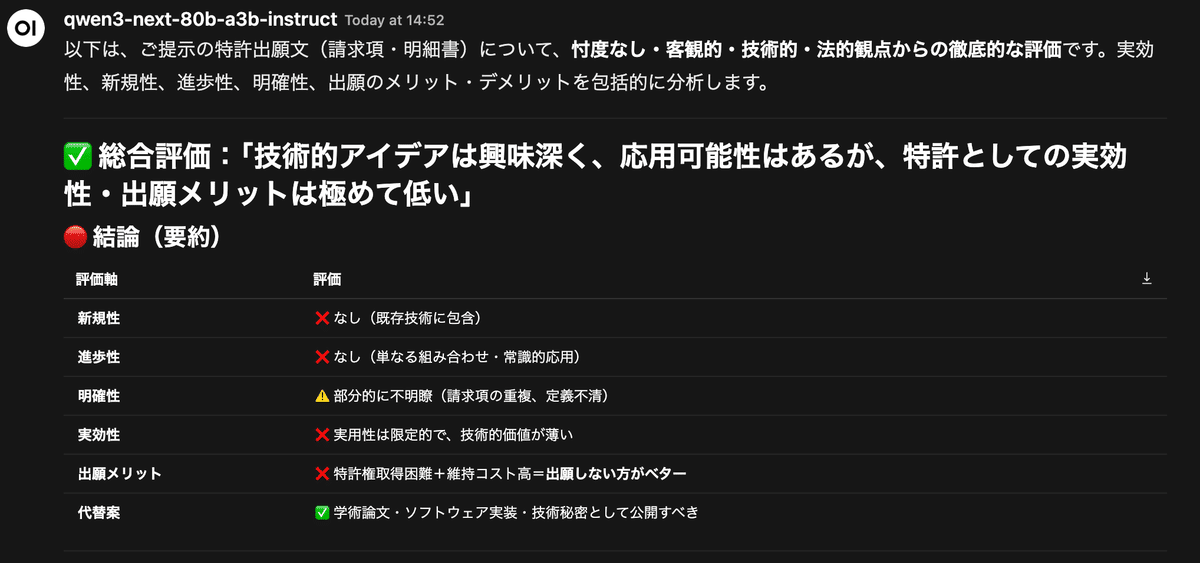
最終評価:★☆☆☆☆(1/5)
行動提案:
🔹 今すぐ特許出願を取りやめ
🔹 論文執筆・コード公開・技術秘密化に集中
これを読んで、私の見立てとも一致していました。
結論:出願しない
理由:新規性・進歩性なし、コストに見合わない
次の行動:研究成果として論文化、コアな技術は秘匿
Qwen3-nextの評価が、自分の考えを明確に言語化してくれた形です。依頼部署への回答も、その日のうちに完了しました。
gpt-oss:詳細だが、結論が出ない
一方、OpenAI社のgpt-ossは、132行にわたる詳細な分析を返してきました。

評価(抜粋):
新規性:6点/10点
進歩性:5点/10点
明瞭性:4点/10点
推奨アクション:
1. 先行技術調査の徹底
2. クレーム構造のリファイン
3. 実施例を充実させる
4. 出願戦略:日本で実用新案→PCT出願で海外展開も検討
結論:
「具体的な実装手法とともにクレーム化すれば、特許取得の可能性は十分にあります。」
読み終えて、私は混乱しました。
結論は「出願すべき」なのか「やめるべき」なのか?
6点/10点は「合格」なのか?
推奨アクションを全部やる必要があるのか?
これをやったら、さらに何週間かかるのか?
つまり、判断が先送りされたのです。
決定的な違い:gpt-oss vs Qwen
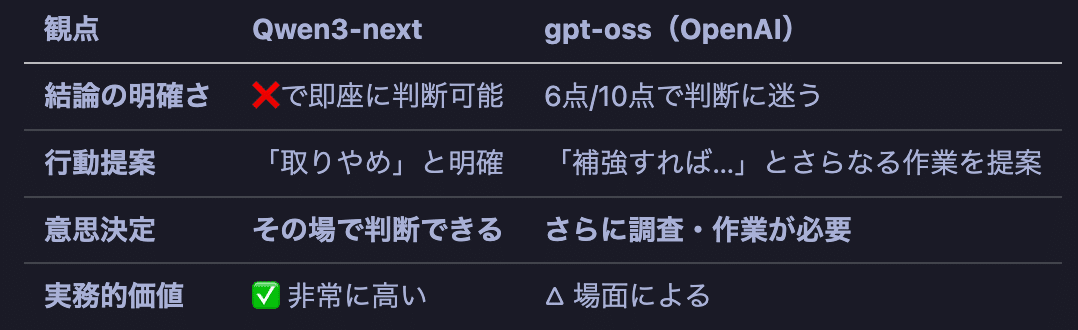
知名度の高いOpenAI社のgpt-ossと、Qwenの回答スタイルは大きく異なりました。
なぜQwen3-nextが実務で役立ったのか
1. 結論をつけて、次に進める
事業会社のDX推進では、意思決定のスピードが命です。
他部署への回答期限がある
経営層への報告がある
次のプロジェクトが待っている
そんな中、「さらに調査が必要」と言われても、時間がないのです。
Qwen3-nextは、結論をつけてくれます。おかげで、その特許の案件は終了し、次の仕事に取り掛かれました。
2. gpt-ossは「永遠に終わらない仕事」を生み出す
gpt-ossの回答は、こう読めます:
「先行技術を調査して、クレームを整理して、実施例を充実させて、出願戦略を練って…」
これは、新たな仕事を生み出しているのです。
先行技術調査:数日~1週間
クレーム整理:専門家との調整
実施例の充実:実験データの再収集
出願戦略:弁理士への相談
気づけば、1ヶ月経っても結論が出ない。そして、他の仕事が滞る。
これでは、DXどころではありません。
3. 「両論併記」は、実務では使えない
gpt-ossは、あらゆる可能性を列挙します。
「〇〇すれば可能性はある」
「△△次第では難しい」
「××を検討すべき」
学術的には正しいのかもしれません。でも、他部署は「で、どうすればいいの?」と聞いています。
Qwen3-nextは、その問いに答えます。「❌ 出願しない方が良い」と。
知名度≠実用性
この実験から分かったこと:
OpenAI社の知名度 ≠ 実務での使いやすさ
詳細な分析 ≠ 意思決定の支援
専門性の高さ ≠ 実用的価値
事業会社のDX推進では、9割の場面で、結論を出してくれるモデルが勝ちます。
モデル選びの基準

事業会社のDX推進者へのメッセージ
他部署の機密データ、もう悩まなくていい
ローカルLLMがあれば:
社内規程に抵触しない(データは外部に出ない)
法務部も承認しやすい(「社内サーバーで完結」と説明できる)
顧客情報も扱える(NDA違反のリスクゼロ)
知名度より、実用性で選ぶ
OpenAI社の知名度は確かに魅力的です。経営層への説明もしやすいでしょう。
でも、実務で本当に役立つのは、結論を出してくれるモデルです。
今回の経験から、私は意思決定の場面ではQwen3-nextを選びます。
30万円の投資は、すぐに回収できる
月額課金なし:ChatGPT Plusなら年間約3万円 × 部署メンバー
時短効果:1件の評価が3分で完了(従来は数日)
意思決定の速さ:「結論が出ない」ストレスからの解放
経営層への稟議も、「機密データを安全に処理できる」という一点で通ります。
まとめ:結論を出してくれるAIが、DXを加速する
今回の実験で分かったこと:
知名度の高さと実務的な使いやすさは別
意思決定の場面では、詳細な分析より明確な結論
モデルごとの回答スタイルの違いを理解して使い分ける
事業会社のDX推進において、最大の壁は「機密データをどう処理するか」です。
ローカルLLMは、その壁を取り払います。
そして、モデル選びは、知名度ではなく「回答の構造」で決めるべきです。
今回、Qwen3-nextは結論を明確に提示してくれました。おかげで、その特許案件は完了し、次の仕事に取り掛かれました。
これが、DXの本質です。
補足情報
実行環境
PC: Ryzen AI Max+ 395搭載機(約30万円)
ツール: OpenWebUI、LM Studio
モデル: gpt-oss-120b-a5b、Qwen3-next-80b-a3b-instruct
(いずれもローカルで動作、MoE型)
詳細は以前の記事を参照してください。
注意事項
この記事で扱った特許は実在しますが、企業への風評被害を避けるため、具体的な内容や企業名は伏せています。あくまでLLMの回答構造の違いを比較する目的です。
個人の所有資産で検証した後に、機会があったので類似の事例で所属企業で検証しています。PC環境・扱った特許は異なります。他の記事についても個人での検証結果のみ記載しています。