
エージェントのための効果的なツールの作成

以下の記事が面白かったので、簡単にまとめました。
1. はじめに
「MCP」は、LLMエージェントに数百もの「ツール」を提供し、現実世界のタスクを解決できるようにします。この記事では、ツールを最大限に活用するための最も効果的な手法について説明します。
まず、以下の方法について説明します。
・ツールのプロトタイプを作成してテスト
・エージェントを用いてツールの包括的な評価を作成して実行
・エージェントと連携してツールの性能を自動的に向上
最後に、高品質な「ツール」を作成するための重要な原則を紹介します。
・実装する (または実装しない) 適切なツールを選択
・機能の明確な境界を定義するためにツールに名前空間を設定
・ツールからエージェントに意味のあるコンテキストを返す
・トークン効率を高めるためにツールの応答を最適化
・ツールの説明と仕様をプロンプトエンジニアリング
2. ツールとは
コンピューティングにおいて、「決定論的システム」は同一の入力に対して常に同じ出力を生成しますが、「非決定論的システム」(エージェントなど) は、多様な出力を生成することがあります。
「ツール」は、決定論的システムと非決定論的エージェント間の契約を反映した新しい種類のソフトウェアです。ユーザーが「今日は傘を持っていくべきでしょうか?」と尋ねると、エージェントは天気予報ツールを呼び出したり、一般知識に基づいて回答したり、あるいは最初に場所を明確にする質問をしたりするかもしれません。エージェントは幻覚を見たり、ツールの使い方を理解できなかったりすることもあります。
これは、エージェント用のソフトウェアを作成する際のアプローチを根本的に見直すことを意味します。他の開発者やシステム用の関数や API を作成するのと同じようにツールやMCPサーバを作成するのではなく、エージェント向けに設計する必要があります。
3. ツールの作成方法
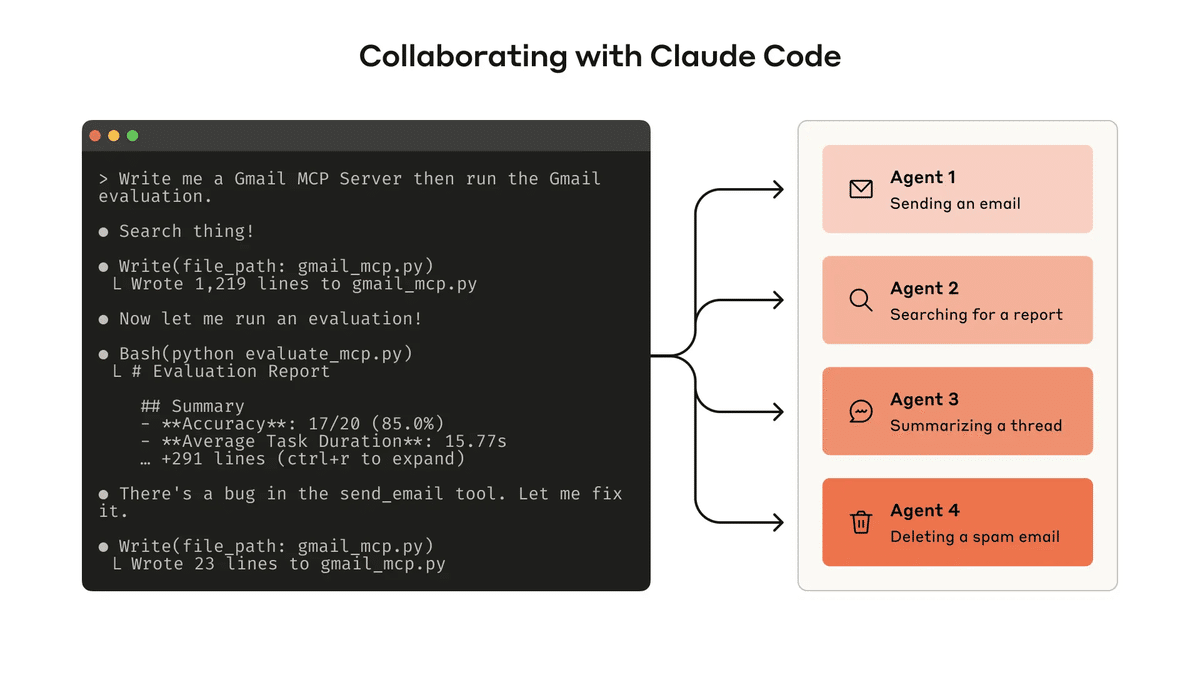
3-1. プロトタイプの作成
はじめに、ツールの簡単なプロトタイプを作成します。
「Claude Code」を使用して「ツール」を開発する場合、ツールが使用するソフトウェアライブラリ、API、SDK (MCP SDK も含む) に関するドキュメントを「Claude」に提供すると役立ちます。LLM対応のドキュメントは、公式ドキュメントの「llms.txt」で見つかることが多いです。
ツールをローカルMCPサーバまたはDXTでラップすると、「Claude Code」または「Claude Desktop」に接続してテストできるようになります。プログラムによるテストのために「Anthropic API」を使用することもできます。
3-2. 評価の実行
次に評価を実行して、「Claude」がツールをどれだけ効果的に活用しているかを測定する必要があります。まずは、実際の使用状況に基づいた評価タスクを多数作成することから始めます。エージェントと協力して結果を分析し、ツールの改善方法を決定することをお勧めします。
詳しくは「tool evaluation cookbook」を参照してください。
3-3. 評価タスクの生成
初期プロトタイプがあれば、「Claude Code」はユーザーの「ツール」を迅速に調査し、数十種類のプロンプトと応答のペアを作成できます。プロンプトは、実際の使用状況に着想を得たもので、現実的なデータソースとサービス (社内ナレッジベースやマイクロサービスなど) に基づく必要があります。ツールのストレステストを十分に行わない、過度に単純化された、あるいは表面的な「サンドボックス」環境は避けることをお勧めします。強力な評価タスクには、複数回 (場合によっては数十回) のツール呼び出しが必要になる場合があります。
強力な評価タスクの例は、次のとおりです。
・来週、Acme Corpの最新プロジェクトについて話し合うため、Janeとの会議をスケジュールしてください。前回のプロジェクト計画会議のメモを添付し、会議室を予約してください。
・顧客ID 9182から、1回の購入試行に対して3回請求されたという報告がありました。関連するログエントリをすべて検索し、同じ問題の影響を受けた他の顧客がいないかどうかを確認してください。
・顧客の Sarah Chenからキャンセルリクエストが提出されました。継続オファーを準備してください。 (1)退職理由、(2)最も魅力的な継続オファー、(3)オファー前に考慮すべきリスク要因を特定する。
簡単な評価タスクの例は、次のとおりです。
・来週、[email protected] とのミーティングをスケジュールする。
・支払いログで purchase_complete と customer_id=9182 を検索する。
・顧客ID 45892 のキャンセルリクエストを見つける。
各評価プロンプトには、検証可能な応答または結果を組み合わせる必要があります。検証ツールは、実際の応答とサンプル応答の文字列の正確な比較のような単純なものから、「Claude」に応答の判断を依頼する高度なものまで様々です。書式、句読点、有効な代替表現などの不自然な違いを理由に正しい応答を拒否するような、過度に厳格な検証ツールは避けてください。
各プロンプトと応答のペアに対して、エージェントがタスク解決時に呼び出すと予想されるツールをオプションで指定することもできます。これにより、エージェントが評価中に各ツールの目的を理解できているかどうかを測定できます。ただし、タスクを正しく解決するには複数の有効なパスが存在する可能性があるため、戦略を過剰に指定したり、過剰適合させたりしないようにしてください。
3-4. 評価の実行
評価は、LLM APIを直接呼び出してプログラム的に実行することをお勧めします。シンプルなエージェントループ (LLM APIとツールの呼び出しを交互にラップするwhileループ) を使用してください。評価タスクごとに1つのループを使用します。各評価エージェントには、単一のタスクプロンプトとツールが与えられます。
評価エージェントのシステムプロンプトでは、エージェントに構造化された応答ブロック (検証用) だけでなく、推論ブロックとフィードバックブロックも出力するように指示することをお勧めします。ツール呼び出しと応答ブロックの前にこれらのブロックを出力するようにエージェントに指示することで、思考連鎖 (CoT) 行動を誘発し、LLMの効果的なインテリジェンスを向上させることができます。
「Claude」と評価を実施する場合は、類似の既成機能に対してインターリーブ思考を有効化できます。これにより、エージェントが特定のツールを使用する理由や使用しない理由を調査し、ツールの説明や仕様における改善点を特定するのに役立ちます。
トップレベルの精度に加えて、個々のツール呼び出しとタスクの合計実行時間、ツール呼び出しの合計回数、トークン消費量の合計、ツールエラーなどの指標も収集することをお勧めします。ツール呼び出しを追跡することで、エージェントが実行する一般的なワークフローを明らかにし、ツール統合の機会を見つけることができます。
3-5. 結果の分析
エージェントは、矛盾したツールの説明から、非効率的なツールの実装、わかりにくいツールのスキーマまで、あらゆる問題を発見し、フィードバックを提供してくれる頼りになるパートナーです。しかし、エージェントのフィードバックや回答に何が欠けているかの方が、何が含まれているかよりも重要である場合が多いことを覚えておいてください。LLMは必ずしも意図したとおりに説明してくれるとは限りません。
エージェントがどこで行き詰まったり混乱したりするかを観察します。評価エージェントの推論とフィードバック (CoT) を読み、問題点を特定します。生のトランスクリプト (ツール呼び出しとツール応答を含む) を確認し、エージェントのCoTに明示的に記載されていない行動を把握します。行間を読むことも重要です。評価エージェントは必ずしも正しい回答や戦略を知っているわけではないことを忘れないでください。
ツール呼び出しのメトリクスを分析します。冗長なツール呼び出しが多い場合は、ページネーションやトークン制限パラメータの適切なサイズ設定が適切である可能性があります。無効なパラメータによるツールエラーが多い場合は、ツールの説明をより明確にしたり、より良い例を使用したりする必要がある可能性があります。「Claude」のウェブ検索ツールをリリースしたとき、「Claude」がツールのクエリパラメータに不必要に2025を追加していたため、検索結果に偏りが生じ、性能が低下していたことが判明しました (ツールの説明を改善することで、「Claude」を正しい方向に導きました)。
3-6. エージェントとの連携
エージェントに結果を分析させ、ツールの改善を任せることもできます。評価エージェントからのトランスクリプトを連結し、「Claude Code」に貼り付けるだけです。「Claude」は、トランスクリプトの分析と多数のツールのリファクタリングを一括で行うエキスパートです。例えば、新しい変更が加えられた場合でも、ツールの実装と説明の一貫性を保つことができます。
実際、この記事で紹介したアドバイスのほとんどは、「Claude Code」を用いて社内ツール実装を繰り返し最適化してきた経験から得たものです。評価は社内ワークスペース上に作成され、実際のプロジェクト、ドキュメント、メッセージなど、社内ワークフローの複雑さを反映しています。
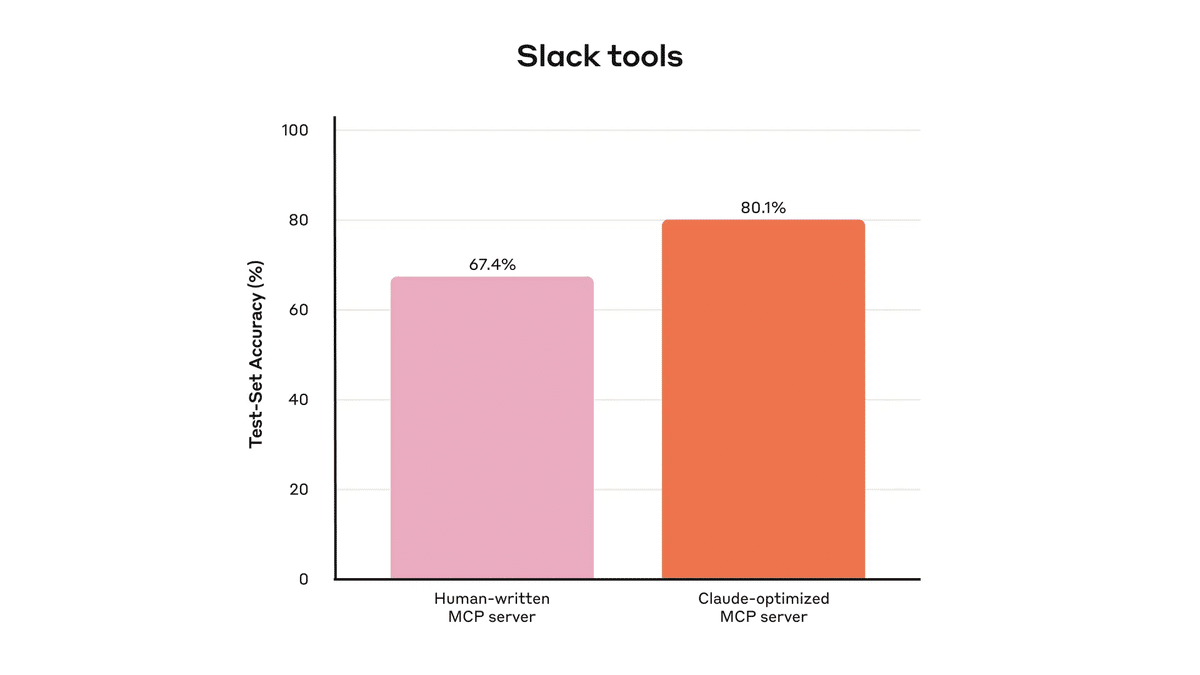
「学習」評価に過剰適合しないように、ホールドアウトテストセットを使用しました。これらのテストセットにより、「専門家」によるツール実装 (研究者が手作業で作成したものでも、「Claude」自身が生成したものでも) で達成した以上の性能向上を実現できることが明らかになりました。
4. 効果的なツールを作成するための原則
4-1. エージェントに適したツールの選択
ツールの数が増えても、必ずしも成果が向上するとは限りません。よく目にするよくある誤りは、既存のソフトウェア機能やAPIエンドポイントを単にラップするだけのツールです。そのツールがエージェントに適しているかどうかは関係ありません。これは、エージェントが従来のソフトウェアとは異なる「アフォーダンス」を持っているためです。つまり、それらのツールを使って実行できる可能性のあるアクションをエージェントが認識する方法が異なるのです。
LLMエージェントは「コンテキスト」が限られています。一方、コンピュータメモリは安価で豊富です。アドレス帳で連絡先を検索するというタスクを考えてみましょう。従来のソフトウェアプログラムは、連絡先リストを1つずつ効率的に保存・処理し、1つずつ確認してから次の処理に移ることができます。
しかし、LLMエージェントがすべての連絡先を返すツールを使用し、その後各連絡先をトークンごとに読み取る必要がある場合、限られたコンテキスト空間を無関係な情報に浪費することになります。より適切で自然なアプローチは、まず関連ページ(おそらくアルファベット順)にスキップすることです。
評価タスクに適合する、影響の大きい特定のワークフローをターゲットとした、思慮深いツールをいくつか構築し、そこから拡張していくことをお勧めします。アドレス帳の場合、list_contactsツールの代わりにsearch_contactsツールやmessage_contactツールを実装することが考えられます。
ツールは機能を統合し、複数の個別の操作 (またはAPI呼び出し) を内部で処理できます。例えば、ツールは関連するメタデータでツールの応答を充実させたり、頻繁に連鎖する複数ステップのタスクを1回のツール呼び出しで処理したりできます。
以下にいくつか例を挙げます。
・list_users、list_events、create_event ツールを実装する代わりに、空き状況を検索してイベントをスケジュールする Schedule_event ツールの実装を検討してください。
・read_logs ツールを実装する代わりに、関連するログ行と関連するコンテキストのみを返す search_logs ツールの実装を検討してください。
get_customer_by_id、list_transactions、list_notes ツールを実装する代わりに、顧客の最新の関連情報をすべて一度にまとめる get_customer_context ツールを実装してください。
・構築する各ツールには、明確で明確な目的があることを確認してください。ツールは、エージェントが人間と同じように、同じ基盤リソースにアクセスできるようにタスクを細分化して解決できるようにする必要があります。同時に、中間出力で消費されるはずだったコンテキストを削減する必要があります。
ツールが多すぎたり重複していると、エージェントが効率的な戦略を追求できなくなる可能性があります。ツールを慎重に選択的に計画することで、大きな成果が得られます。
4-2. ツールの名前空間設定
AIエージェントは、数十台のMCPサーバと数百種類のツール (他の開発者のツールも含む) にアクセスする可能性があります。ツールの機能が重複していたり、目的が曖昧だったりすると、エージェントはどのツールを使用すべきか混乱する可能性があります。
名前空間設定( 関連するツールを共通のプレフィックスでグループ化すること) は、多くのツール間の境界を明確にするのに役立ちます。MCPクライアントでは、デフォルトでこの設定が行われている場合があります。例えば、サービス別(例:asana_search、jira_search)やリソース別(例:asana_projects_search、asana_users_search)にツールの名前空間を設定すると、エージェントは適切なツールを適切なタイミングで選択できるようになります。
プレフィックスベースとサフィックスベースのどちらの名前空間を選択するかは、ツール使用評価に大きな影響を与えることがわかりました。影響はLLMによって異なるため、ご自身の評価に基づいて命名規則を選択することをお勧めします。
エージェントが間違ったツールを呼び出したり、正しいツールを間違ったパラメータで呼び出したり、ツールの呼び出し数が少なすぎたり、ツールの応答を誤って処理したりする可能性があります。タスクの自然な細分化を反映した名前を持つツールを厳選して実装することで、エージェントのコンテキストに読み込まれるツールとツールの説明の数を削減すると同時に、エージェントのコンテキストからツール呼び出し自体にエージェントの計算負荷を軽減できます。これにより、エージェントがミスを犯すリスクが全体的に軽減されます。
4-3. ツールから意味のあるコンテキストを返す
ツール実装では、エージェントに重要な情報のみを返すように注意する必要があります。柔軟性よりもコンテキストの関連性を優先し、低レベルの技術識別子 (例:uuid、256px_image_url、mime_type) は避けるべきです。name、image_url、file_type などのフィールドは、エージェントの下流のアクションや応答に直接影響を与える可能性がはるかに高くなります。
エージェントは、難解な識別子よりも、自然言語の名前、用語、識別子の方がはるかにうまく処理できる傾向があります。任意の英数字UUIDを、より意味的に意味があり解釈しやすい言語 (あるいは0から始まるIDスキーム) に解決するだけで、幻覚が減少し、「Claude」の検索タスクにおける精度が大幅に向上することが分かっています。
場合によっては、エージェントは、下流のツール呼び出しをトリガーするためだけでも、自然言語と技術識別子の両方の出力を柔軟に操作する必要があることがあります (例:search_user(name=’jane’) → send_message(id=12345))。ツールでシンプルな response_format 列挙型パラメータを公開することで、両方を有効にできます。これにより、エージェントはツールが「簡潔な」応答を返すか「詳細な」応答を返すかを制御できます。
GraphQLのように、受信する情報を正確に選択できるのと同様に、より多くのフォーマットを追加することで、さらに柔軟性を高めることができます。ツールの応答の詳細度を制御するための ResponseFormat 列挙型の例を以下に示します。
enum ResponseFormat {
DETAILED = "detailed",
CONCISE = "concise"
}詳細なツール応答の例 (206トークン) を以下に示します。
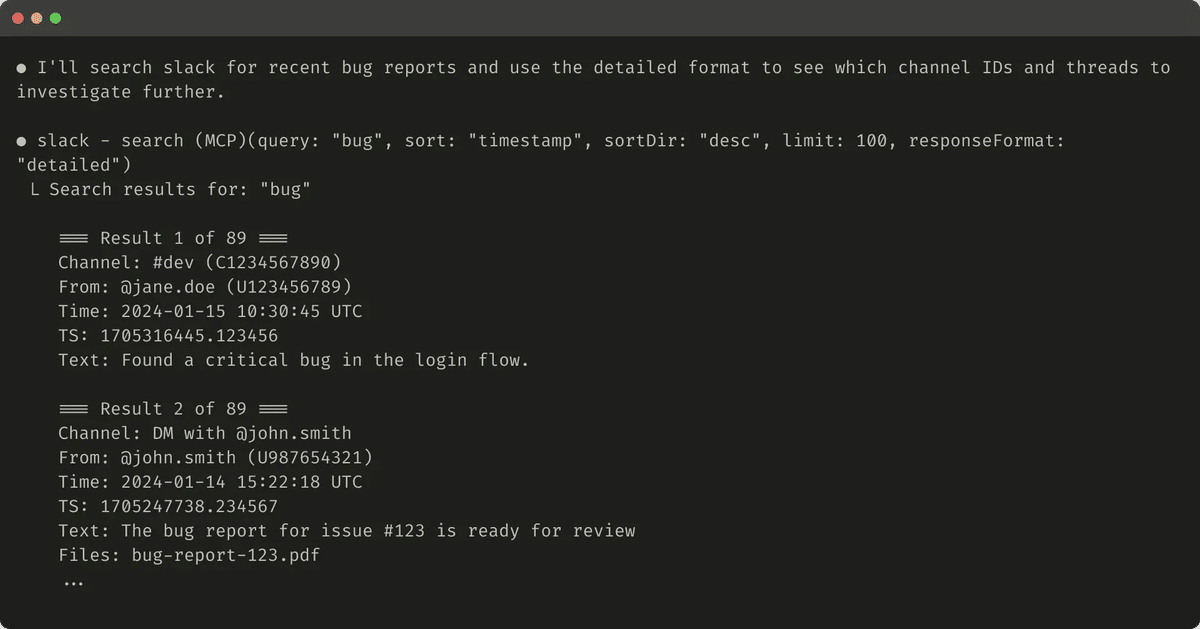
簡潔なツール応答の例 (72トークン) を次に示します。
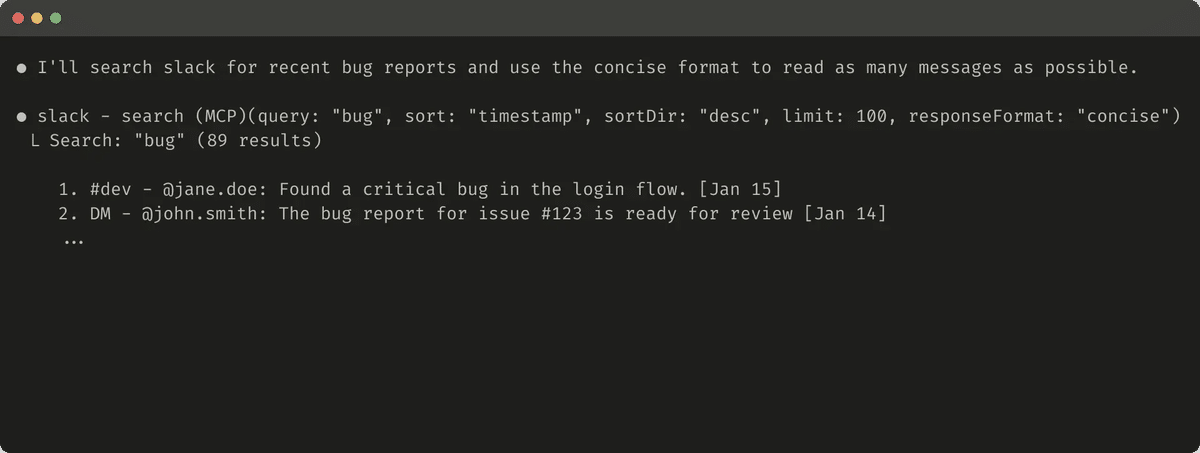
ツールの応答構造 (XML、JSON、Markdownなど) も評価性能に影響を与える可能性があります。万能の解決策はありません。これは、LLMが次トークン予測に基づいて学習されており、学習データと一致する形式でより良い性能を発揮する傾向があるためです。最適な応答構造は、タスクやエージェントによって大きく異なります。自身の評価に基づいて最適な応答構造を選択することをお勧めします。
4-4. トークン効率のためのツール応答の最適化
コンテキストの質を最適化することは重要ですが、ツールの応答でエージェントに返されるコンテキストの量を最適化することも重要です。
大量のコンテキストを消費する可能性のあるツール応答については、適切なデフォルトパラメータ値を用いたページ区切り、範囲選択、フィルタリング、および/または切り捨ての組み合わせを実装することをお勧めします。「Claude Code」では、ツールの応答をデフォルトで25,000トークンに制限しています。エージェントの有効なコンテキスト長は時間とともに増加すると予想されますが、コンテキスト効率の高いツールの必要性は今後も変わりません。
応答を切り捨てる場合は、エージェントに適切な指示を与えるようにしてください。知識検索タスクにおいて、単一の広範な検索ではなく、小規模でターゲットを絞った検索を多数行うなど、よりトークン効率の高い戦略を追求するようエージェントに直接促すことができます。同様に、ツール呼び出しでエラーが発生した場合 (たとえば、入力検証中)、エラー応答をプロンプトエンジニアリングすることで、分かりにくいエラーコードやトレースバックではなく、具体的かつ実用的な改善策を明確に伝えることができます。
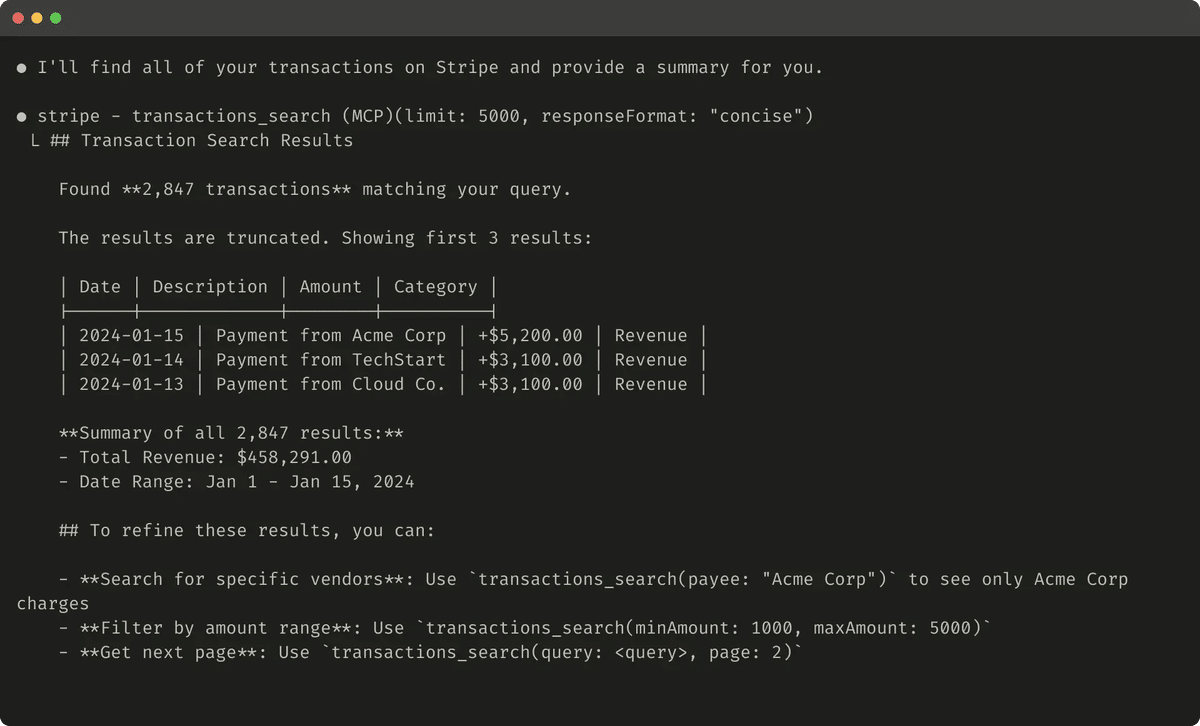
以下は、切り捨てられたツール応答の例です。
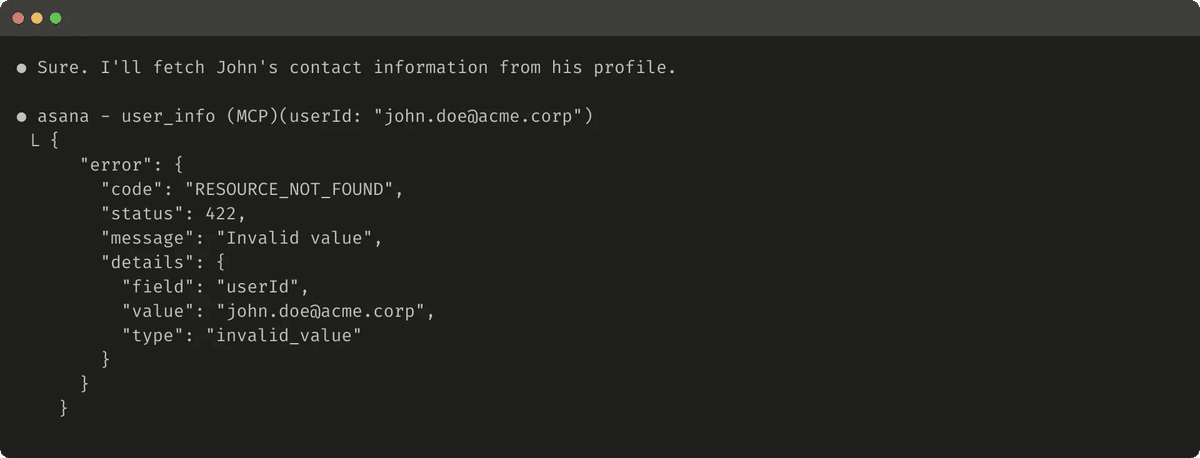
役に立たないエラー応答の例を次に示します。
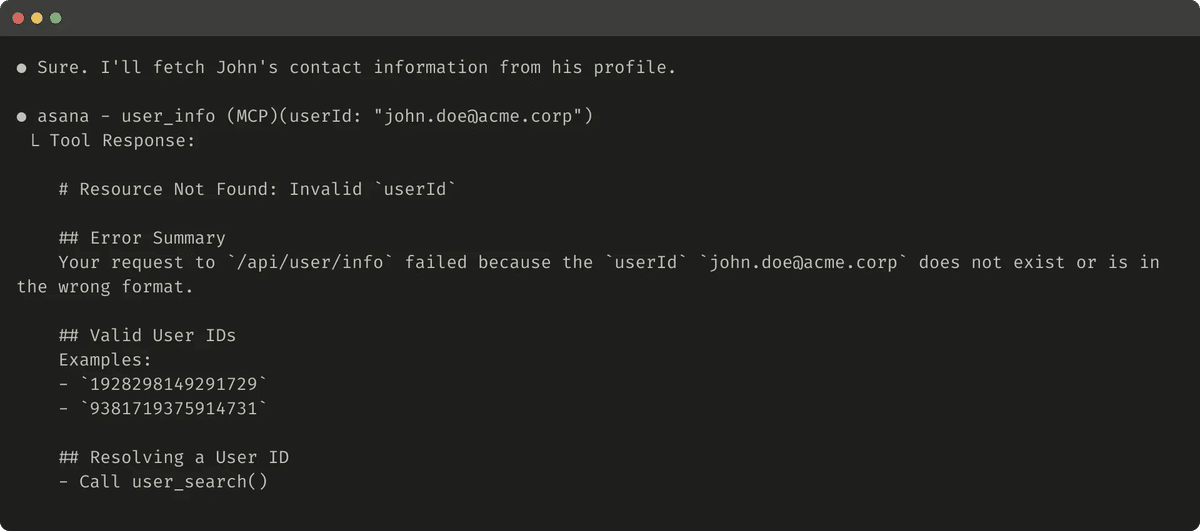
役に立つエラー応答の例を次に示します。
4-5. ツールの説明をプロンプトエンジニアリング
ツールの説明と仕様をプロンプトエンジニアリングする方法について説明します。これらはエージェントのコンテキストに読み込まれるため、エージェントを効果的にツールを呼び出す行動へと導くことができます。
ツールの説明と仕様を作成する際には、チームの新入社員にどのようにツールを説明するかを考えてみましょう。特殊なクエリ形式、ニッチな用語の定義、基盤となるリソース間の関係性など、暗黙的に持ち込む可能性のあるコンテキストを考慮し、明示的に記述します。想定される入出力を明確に記述 (および厳密なデータモデルで強制) することで、曖昧さを回避します。特に、入力パラメータには明確な名前を付ける必要があります。userではなくuser_idというパラメータを試してください。
評価を行うことで、プロンプトエンジニアリングの効果をより確実に測定できます。ツールの説明を少し改良するだけで、劇的な改善が期待できます。 「Claude Sonnet 3.5」は、ツールの説明を厳密に改良した結果、「SWE-bench Verified」において最先端の性能を達成しました。これにより、エラー率が大幅に削減され、タスク完了率も向上しました。
ツール定義に関するその他のベストプラクティスについては、「Developer Guide」を参照してください。Claude用のツールを開発している場合は、ツールがClaudeのシステムプロンプトに動的にロードされる方法についてもお読みください。最後に、MCPサーバ用のツールを開発している場合は、ツールアノテーションを使用することで、オープンワールドアクセスを必要とするツールや破壊的な変更を行うツールを特定できます。