BOTS is a unified framework for Bayesian Online Task Selection in LLM reinforcement finetuning.
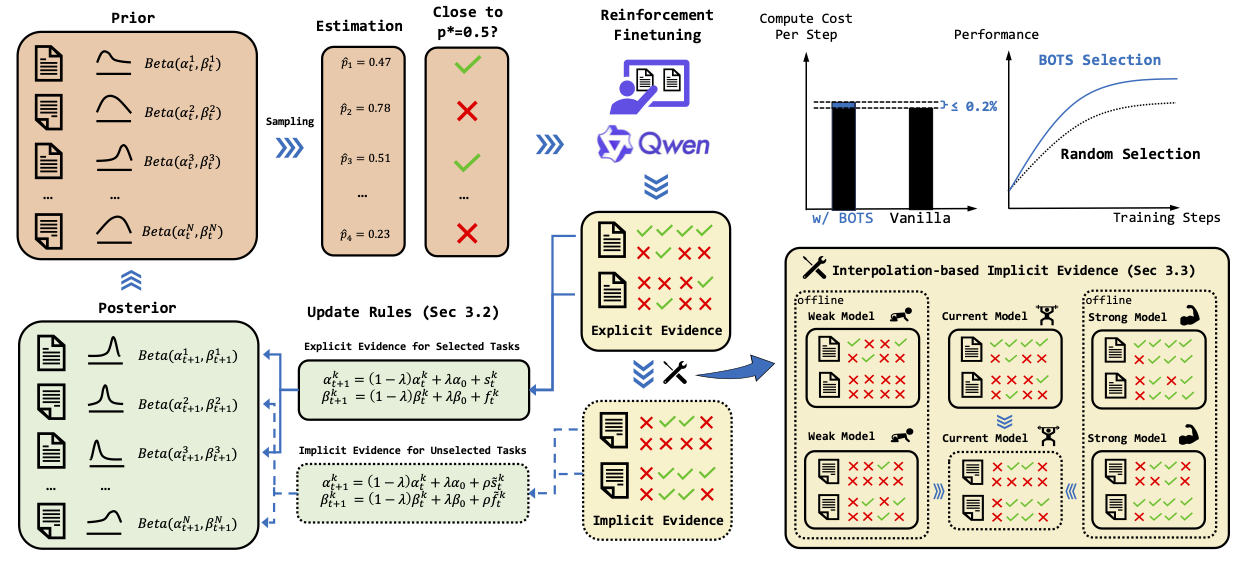
BOTS operates in a continuous loop of task selection, model training, and posterior updating.
(1) Selection: Thompson sampling from the posterior beliefs selects a batch of tasks whose estimated success probabilities are near a target difficulty (e.g.,
Ensure Trinity-RFT is well installed (Installation Guide). No extra dependence is required.
Download the model your want to train (e.g., Qwen2.5-1.5B-Instruct).
Download the GURU dataset. Also refer to the Data Preparation Guide and the Tech Report provided by the LLM360 team.
Remember to modify the model/data path in bots.yaml and random.yaml accordingly.
Modify ref_eval_collect.yaml to set the reference model you want to evaluate, e.g., Qwen2.5-1.5B-Instruct.
Launch evaluation by executing:
BOTS_REF_EVAL_LOG_FILE="path/to/save/eval/logs" trinity run --config examples/bots/ref_eval_collect.yaml --plugin-dir examples/bots/workflowThe evaluation logs will be saved at the specified location. Then integrate the evaluation results as a new column into the original dataset:
python examples/bots/ref_eval_collect.py \
--data-path <your/path/to/original/dataset> \
--ref-eval-path <your/path/to/bots_ref_eval_log.jsonl> \
--ref-eval-key <column name, e.g., qwen2.5_1.5b_pass_rate>Remember to update task_selector.feature_keys in bots.yaml.
Launch training by executing:
trinity run --config examples/bots/bots.yamlThe improvement over random selection baseline can be stably obtained 🤖🤖🤖.
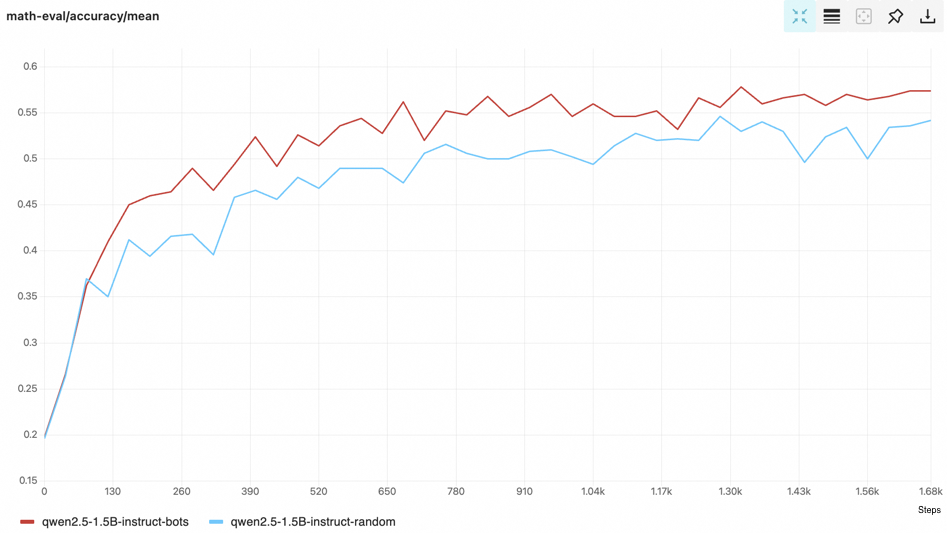
For complete reproduction of the results in our paper, please use the verl version implementation available here.
If you find the repo helpful, please cite:
@misc{TrinityRFT,
title={Trinity-RFT: A General-Purpose and Unified Framework for Reinforcement Fine-Tuning of Large Language Models},
author={Xuchen Pan and Yanxi Chen and Yushuo Chen and Yuchang Sun and Daoyuan Chen and Wenhao Zhang and Yuexiang Xie and Yilun Huang and Yilei Zhang and Dawei Gao and Weijie Shi and Yaliang Li and Bolin Ding and Jingren Zhou},
year={2025},
eprint={2505.17826},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2505.17826},
}
@misc{BOTS,
title={BOTS: A Unified Framework for Bayesian Online Task Selection in LLM Reinforcement Finetuning},
author={Qianli Shen and Daoyuan Chen and Yilun Huang and Zhenqing Ling and Yaliang Li and Bolin Ding and Jingren Zhou},
year={2025},
eprint={2510.26374},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2510.26374},
}