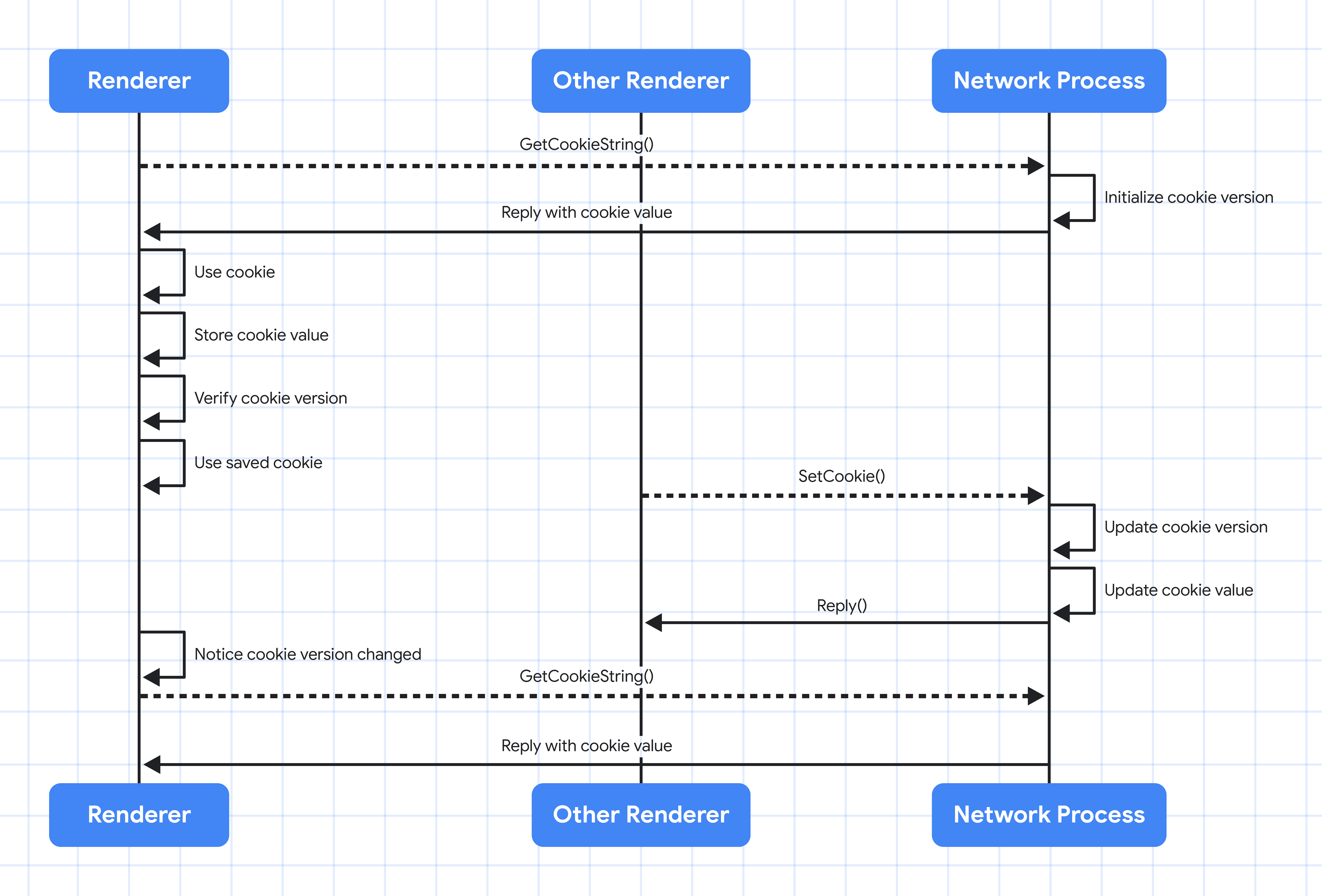
レポートの生成と送信の仕組み。
Reporting API でモニタリングできるエラーには、次のようなものがあります。
Reporting API は、HTTP レスポンス ヘッダーで有効化と設定を行います。つまり、ブラウザがレポートを送信するエンドポイントと、モニタリングするエラータイプを HTTP レスポンス ヘッダーで宣言します。ブラウザは、レポートのリストをペイロードとする POST リクエストによって、レポートをエンドポイントに送信します。
設定の例 :
# CSP 違反レポート、Document-Policy 違反レポート、非推奨レポートを受け取る設定の例
Reporting-Endpoints: main-endpoint="https://reports.example/main", default="https://reports.example/default "
# CSP 違反と Document-Policy 違反を `main-endpoint` に送信する
注 : "report-only" モードをサポートするポリシーもあります。このポリシーでは、レポートは送信されますが、実際の制限は適用されません。これは、ポリシーが効果的に機能しているかどうかを判断する際に役立ちます。
ポリシーを report-only モード でロールアウトします(CSP report-only モードの例 )。こうすると、ブラウザはクライアント側のコードを通常どおり実行するよう指示しつつ、ポリシーが適用された場合に違反となるイベントの情報を収集します。この情報は、レポートのエンドポイントに送信される違反レポートに集約されます。
違反レポートをトリアージし、ポリシーに準拠していないコードの場所にリンクします。たとえば、危険な API を使っていたり、ユーザーデータとコードが混在するパターンを使っていたりするため、セキュリティ ポリシーに準拠していないコードベースがあるかもしれません。
特定したコードをリファクタリングして準拠させます。たとえば、危険な API を安全なバージョンに置き換えたり、ユーザー入力をコードと混在させないようにしたりします。こうしたリファクタリングにより、危険なコーディング パターンが減り、コードベースのセキュリティ態勢が向上します。
すべてのコードを特定し、リファクタリングが終わった段階で、report-only モード からポリシーを削除し、完全に適用します。通常のロールアウトでは、手順 1~3 を繰り返し、すべての違反レポートを確実にトリアージします。
注 : ポリシーで禁止されているアクションを行おうとすると、違反レポートが生成されます。たとえば、あるページに CSP を設定しているにもかかわらず、CSP で許可されていないスクリプトを読み込もうとする場合です。Reporting API で生成されるレポートのほとんどは違反レポートですが、それがすべてではありません。その他のタイプには、非推奨レポートやクラッシュ レポートなどがあります。詳細については、ユースケースとレポートタイプ をご覧ください。
残念ながら、違反レポートのストリームにはノイズが紛れ込むことがよくあります。その場合、準拠していないコードを見つけることが難しくなる可能性があります。たとえば、多くのブラウザ拡張機能、マルウェア、ウィルス対策ソフトウェア、開発ツールのユーザーは、DOM にサードパーティのコードを挿入したり、禁止された API を使ったりしています。挿入されるコードがポリシーに準拠していない場合、コードベースにリンクされていない対策不可能な違反レポートになる可能性があります。そのため、レポートのトリアージが困難になり、すべてのコードを確実に準拠させてから新しいポリシーを適用するのが難しくなります。
Google は長年にわたり、違反レポートを収集して活用し、それをまとめて 根本原因に集約するための多くの技術を開発してきました ここでは、デベロッパーが違反レポートのノイズを除外できる技術の中から、特に役立つ技術の概要を紹介します。
根本原因に注目する
ブラウザのタブが使われている間に、ポリシーに準拠していないコードが何度も実行されることはよくあります。それが発生するたびに、新しい違反レポートが作成され、キューイングされて、レポートのエンドポイントに送信されます。これが起きると、冗長な情報を含む大量のレポートができてしまいます。そこで、違反レポートをクラスタにグループ化することで、個々の違反を意識することなく、根本原因について考えることができます。根本原因の方が理解しやすいので、有効なリファクタリング方法を探す時間を短縮できます。
例を通して、違反がどのようにグループ化されるのかを確認してみましょう。たとえば、インライン JavaScript イベント ハンドラの使用を禁止する report-only の CSP が導入されているとします。違反レポートは、該当するハンドラのすべてのインスタンスについて作成され、次のフィールドが設定されます。
blockedURL フィールドには、inline が設定されます。これは違反の種類を表します。scriptSample フィールドには、フィールド内のイベント ハンドラの内容の最初の数バイトが設定されます。documentURL フィールドには、現在のブラウザタブの URL が設定されます。
ほとんどの場合、この 3 つのフィールドで、特定の URL のインライン ハンドラを一意に識別できます。他のフィールドの値が異なる場合でも同様です。こういったことがよく起こるのは、トークンやタイムスタンプなどのランダムな値をページをまたいで使う場合です。前述のようなフィールドの値は、アプリケーションやフレームワークによって微妙に異なる場合があるため、レポート値をあいまい一致させることができれば、手間を省きつつ、違反をクラスタにグループ化して対策につなげることができます。必要に応じて、URL フィールドに既知のプレフィックスがある違反をグループ化することができます。たとえば、URL が chrome-extension、moz-extension、safari-extension で始まるすべての違反をグループ化すると、根本原因がコードベース以外のブラウザ拡張機能である違反を、高い信頼性で特定できます。
独自のグループ化戦略を策定すれば、トリアージが必要な違反報告の数を大幅に減らし、根本原因に注目することができます。通常は、関心のある種類の違反を一意に識別するフィールドを選び、そのフィールドを使って、特に重要な根本原因に優先順位をつけられるようにする必要があります。
環境情報を活用する
対策不可能な違反レポートと対策可能な違反レポートを区別するもう 1 つの方法が、環境情報です。このデータは、レポートのエンドポイントへのリクエストには含まれますが、違反レポート自体には含まれません。環境情報からクライアント設定におけるノイズ源を判別できる可能性があるので、トリアージに役立つかもしれません。
ユーザー エージェントまたはユーザー エージェント クライアント ヒント : ユーザー エージェントは、対策不可能な違反の大きな兆候です。たとえば、クローラ、ボット、一部のモバイルアプリなどは、サポート対象のブラウザ エンジンとは動作が異なり、カスタムのユーザー エージェントを使っているので、他では起きない違反が発生する可能性があります。それ以外にも、特定のブラウザでのみ発生する違反や、ナイトリー ビルドによる変更や新バージョンのブラウザによって発生する違反もあります。ユーザー エージェント情報がなければ、こういった違反を調査することは非常に困難になります。信頼できるユーザー : エンドポイントが違反の発生したドキュメントと same-site である場合、Reporting API がレポート エンドポイントに対して行うリクエストに利用可能な Cookie が添付されます。Cookie を取得すると、違反が起きたユーザーの種類を特定する際に役立ちます。対策すべき違反の多くは、会社の従業員やウェブサイト管理者など、信頼できるユーザーによるものであり、これらのユーザーが侵略的な拡張機能をインストールしたり、マルウェアに感染していたりすることはないでしょう。レポート エンドポイントから認証情報を取得できない場合は、まず信頼できるユーザーを対象に report-only ポリシーを設定してみましょう。そうすることで、対策すべき違反の基準を明確にしてから、ポリシーを一般公開することができます。ユニーク ユーザー数 : 一般原則として、典型的な機能やコードパスのユーザーからは、ほぼ同じ違反が生成されるといえます。そのため、少数のユーザーでしか発生していない違反は除外候補とすることができます。つまり、アプリケーションのコードではなく、ユーザーの特定の設定が問題である可能性があるということです。「ユーザー数をカウントする」方法の 1 つは、違反を報告したユニーク IP アドレス数を記録することです。近似カウント アルゴリズムは使いやすく、特定の IP アドレスを追跡せずにこの情報を収集できます。たとえば、HyperLogLog アルゴリズムは、わずか数バイトで、信頼度高く、集合内のおおまかな一意の要素数を数えることができます。
違反をソースコードにマッピングする(高度な内容)
違反のタイプによっては、source_file フィールドまたはそれと同等のフィールドが含まれます。このフィールドは、違反の原因となった JavaScript ファイルを表し、通常は行番号と列番号が付いています。これらの 3 ビットデータは高品質の信号であり、リファクタリングが必要なコードの行を直接指すことができます。
ただし、コンパイルや最小化のために、ブラウザがフェッチしたソースファイルがコードベースに直接マッピングできなくなることもよくあります。その場合は、JavaScript ソースマップを使って、デプロイされたファイルとオーサリングされたファイル の間で行番号と列番号をマッピングするとよいでしょう。すると、違反レポートがソースコードの行に直接変換されるので、非常に対策しやすいレポート グループと根本原因が生成されます。
独自のソリューションを確立する
Reporting API は、セキュリティ違反、非推奨の API 呼び出し、ブラウザの介入などのブラウザ側イベントを、イベントごとに指定されたエンドポイントに送信します。ただし、前のセクションで説明したように、そのレポートから実際の問題を抽出するには、データ処理システムが必要です。
幸いなことに、さまざまな方法で必要なアーキテクチャを設定できるようになっており、オープンソースのプロダクトもあります。必要なシステムの基本的な要素は次のとおりです。
API エンドポイント : HTTP リクエストを受け取り、JSON 形式でレポートを処理するウェブサーバーストレージ : 受け取ったレポートやパイプラインで処理したレポートを格納するストレージ サーバーデータ パイプライン : ノイズを除去し、必要なメタデータを抽出して集約するパイプラインデータ視覚化ツール : 処理したレポートから知見を得るためのツール
以上の各コンポーネントのソリューションは、パブリック クラウド プラットフォーム、SaaS サービス、オープンソース ソフトウェアとして利用できます。詳細については、
代替ソリューション のセクションをご覧ください。また、次のセクションでは、サンプル アプリケーションの概要を説明します。
サンプル アプリケーション : Reporting API プロセッサ
ブラウザからレポートを受け取る方法と、受け取ったレポートを処理する方法を理解できるように、小さなサンプル アプリケーション を作成しました。このアプリケーションで、ブラウザが送信したレポートからウェブ アプリケーションのセキュリティ問題を抽出するために必要なプロセスを示します。具体的には、以下のプロセスになります。
このサンプルでは、Google Cloud を使っていますが、各コンポーネントはお好みのテクノロジーに置き換えることができます。サンプル アプリケーションの概要を次の図に示します。
緑色のボックスは、独自に実装する必要があるコンポーネントです。 フォワーダ(forwarder) はシンプルなウェブサーバーであり、JSON 形式のレポートを受け取り、それを Bigtable 用のスキーマに変換します。 ビームコレクタ(beam-collector) はシンプルな Apache Beam パイプラインであり、ノイズの多いレポートをフィルタリングし、関連するレポートを集約して、CSV ファイルとして保存します。この 2 つのコンポーネントは、Reporting API からのレポートを有効利用するうえで重要な役割を果たしています。
実際に試す
これは実際に実行できるサンプル アプリケーションなので、すべてのコンポーネントを Google Cloud プロジェクトにデプロイし、自分で仕組みを確認することができます。サンプル システムを設定するための詳細な前提条件と手順は、
README.md ファイルに記載されています。
代替ソリューション
ここで共有したオープンソース ソリューション以外にも、Reporting API を簡単に使えるようにするツールがいくつも用意されています。次のようなものがあります。
Sentry や Datadog などのアプリケーション エラー モニタリング プラットフォーム
代替案を選択する際は、価格だけでなく、次の点を考慮するようにしましょう。
アプリケーションの URL をサードパーティのレポート収集ツールに渡しても構わないでしょうか?ブラウザが URL から機密情報を取り除いたとしても、機密情報はこのように漏洩する可能性 があります。アプリケーションにとってリスクが高すぎると思われる場合は、独自のレポート エンドポイントを運用してください。 収集ツールは、必要なすべてのレポートタイプをサポートしていますか?たとえば、すべてのレポート エンドポイント ソリューションが COOP/COEP 違反レポートをサポートしているわけではありません。
まとめ
この記事では、ウェブ デベロッパーが Reporting API を使ってクライアント側の問題を収集する方法と、収集したレポートから実際の問題を抽出する際の課題について説明しました。また、その課題を解決するために Google がどのようにレポートをフィルタリングして処理しているかを説明し、同様のソリューションを実現する際に利用できるオープンソース プロジェクトを紹介しました。この情報が役立ち、Reporting API を活用するデベロッパーが増え、結果としてウェブサイトの安全性と持続可能性が向上することを願っています。
学習リソース
Reviewed by
Eiji Kitamura - Developer Relations Team
この記事は Yoshi Yamaguchi、Santiago Díaz、Maud Nalpas、Eiji Kitamura による Google Security Blog の記事 "Uncovering potential threats to your web application by leveraging security reports " を元に翻訳・加筆したものです。詳しくは元記事をご覧ください。
新たなウェブ標準である Reporting API は、本番ウェブサイトにアクセスするブラウザで発生する問題をレポートする汎用的な仕組みを提供します。受け取るレポートでは、世界中のユーザーのブラウザで発生するセキュリティ違反やまもなく非推奨になる API などの問題が詳しく説明されています。
多くの場合は、HTTP ヘッダーでエンドポイント URL を指定するだけでレポートを収集できます。するとブラウザは、皆さんにとって関心のある問題が含まれたレポートをエンドポイントに自動転送し始めます。ただし、レポートの処理や分析はそれほど簡単ではありません。たとえば、エンドポイントには大量のレポートが送られてくる可能性がありますが、そのすべてが根本的な問題の特定に役立つわけではない場合があります。そのような状況では、問題を抽出して修正するのは非常に困難かもしれません。
このブログ投稿では、Google セキュリティ チームがどのように Reporting API を使って潜在的な問題を検出し、実際の問題を特定しているかを紹介します。また、Google と同じようなアプローチで簡単にレポートの処理や対策ができるように、オープンソースのソリューションも紹介します。
Reporting API の仕組み
本番環境のユーザーのブラウザでしか発生しないエラーもあります。もちろん、皆さんはユーザーのブラウザにアクセスすることはできません。こういったエラーは、ローカルで、あるいは開発中に見かけることはありません。実際のユーザーやネットワーク、デバイスがどのような状態になっているかわからないからです。Reporting API を使えば、ブラウザを直接利用してこういったエラーをモニタリングできます。つまり、ブラウザがエラーをキャッチし、エラーレポートを生成して、指定したエンドポイントに送信してくれます。
レポートの生成と送信の仕組み。
Reporting API でモニタリングできるエラーには、次のようなものがあります。
Reporting API は、HTTP レスポンス ヘッダーで有効化と設定を行います。つまり、ブラウザがレポートを送信するエンドポイントと、モニタリングするエラータイプを HTTP レスポンス ヘッダーで宣言します。ブラウザは、レポートのリストをペイロードとする POST リクエストによって、レポートをエンドポイントに送信します。
設定の例 :
# CSP 違反レポート、Document-Policy 違反レポート、非推奨レポートを受け取る設定の例
Reporting-Endpoints: main-endpoint="https://reports.example/main", default="https://reports.example/default "
# CSP 違反と Document-Policy 違反を `main-endpoint` に送信する
注 : "report-only" モードをサポートするポリシーもあります。このポリシーでは、レポートは送信されますが、実際の制限は適用されません。これは、ポリシーが効果的に機能しているかどうかを判断する際に役立ちます。
ポリシーを report-only モード でロールアウトします(CSP report-only モードの例 )。こうすると、ブラウザはクライアント側のコードを通常どおり実行するよう指示しつつ、ポリシーが適用された場合に違反となるイベントの情報を収集します。この情報は、レポートのエンドポイントに送信される違反レポートに集約されます。
違反レポートをトリアージし、ポリシーに準拠していないコードの場所にリンクします。たとえば、危険な API を使っていたり、ユーザーデータとコードが混在するパターンを使っていたりするため、セキュリティ ポリシーに準拠していないコードベースがあるかもしれません。
特定したコードをリファクタリングして準拠させます。たとえば、危険な API を安全なバージョンに置き換えたり、ユーザー入力をコードと混在させないようにしたりします。こうしたリファクタリングにより、危険なコーディング パターンが減り、コードベースのセキュリティ態勢が向上します。
すべてのコードを特定し、リファクタリングが終わった段階で、report-only モード からポリシーを削除し、完全に適用します。通常のロールアウトでは、手順 1~3 を繰り返し、すべての違反レポートを確実にトリアージします。
注 : ポリシーで禁止されているアクションを行おうとすると、違反レポートが生成されます。たとえば、あるページに CSP を設定しているにもかかわらず、CSP で許可されていないスクリプトを読み込もうとする場合です。Reporting API で生成されるレポートのほとんどは違反レポートですが、それがすべてではありません。その他のタイプには、非推奨レポートやクラッシュ レポートなどがあります。詳細については、ユースケースとレポートタイプ をご覧ください。
残念ながら、違反レポートのストリームにはノイズが紛れ込むことがよくあります。その場合、準拠していないコードを見つけることが難しくなる可能性があります。たとえば、多くのブラウザ拡張機能、マルウェア、ウィルス対策ソフトウェア、開発ツールのユーザーは、DOM にサードパーティのコードを挿入したり、禁止された API を使ったりしています。挿入されるコードがポリシーに準拠していない場合、コードベースにリンクされていない対策不可能な違反レポートになる可能性があります。そのため、レポートのトリアージが困難になり、すべてのコードを確実に準拠させてから新しいポリシーを適用するのが難しくなります。
Google は長年にわたり、違反レポートを収集して活用し、それをまとめて 根本原因に集約するための多くの技術を開発してきました ここでは、デベロッパーが違反レポートのノイズを除外できる技術の中から、特に役立つ技術の概要を紹介します。
根本原因に注目する
ブラウザのタブが使われている間に、ポリシーに準拠していないコードが何度も実行されることはよくあります。それが発生するたびに、新しい違反レポートが作成され、キューイングされて、レポートのエンドポイントに送信されます。これが起きると、冗長な情報を含む大量のレポートができてしまいます。そこで、違反レポートをクラスタにグループ化することで、個々の違反を意識することなく、根本原因について考えることができます。根本原因の方が理解しやすいので、有効なリファクタリング方法を探す時間を短縮できます。
例を通して、違反がどのようにグループ化されるのかを確認してみましょう。たとえば、インライン JavaScript イベント ハンドラの使用を禁止する report-only の CSP が導入されているとします。違反レポートは、該当するハンドラのすべてのインスタンスについて作成され、次のフィールドが設定されます。
blockedURL フィールドには、inline が設定されます。これは違反の種類を表します。scriptSample フィールドには、フィールド内のイベント ハンドラの内容の最初の数バイトが設定されます。documentURL フィールドには、現在のブラウザタブの URL が設定されます。
ほとんどの場合、この 3 つのフィールドで、特定の URL のインライン ハンドラを一意に識別できます。他のフィールドの値が異なる場合でも同様です。こういったことがよく起こるのは、トークンやタイムスタンプなどのランダムな値をページをまたいで使う場合です。前述のようなフィールドの値は、アプリケーションやフレームワークによって微妙に異なる場合があるため、レポート値をあいまい一致させることができれば、手間を省きつつ、違反をクラスタにグループ化して対策につなげることができます。必要に応じて、URL フィールドに既知のプレフィックスがある違反をグループ化することができます。たとえば、URL が chrome-extension、moz-extension、safari-extension で始まるすべての違反をグループ化すると、根本原因がコードベース以外のブラウザ拡張機能である違反を、高い信頼性で特定できます。
独自のグループ化戦略を策定すれば、トリアージが必要な違反報告の数を大幅に減らし、根本原因に注目することができます。通常は、関心のある種類の違反を一意に識別するフィールドを選び、そのフィールドを使って、特に重要な根本原因に優先順位をつけられるようにする必要があります。
環境情報を活用する
対策不可能な違反レポートと対策可能な違反レポートを区別するもう 1 つの方法が、環境情報です。このデータは、レポートのエンドポイントへのリクエストには含まれますが、違反レポート自体には含まれません。環境情報からクライアント設定におけるノイズ源を判別できる可能性があるので、トリアージに役立つかもしれません。
ユーザー エージェントまたはユーザー エージェント クライアント ヒント : ユーザー エージェントは、対策不可能な違反の大きな兆候です。たとえば、クローラ、ボット、一部のモバイルアプリなどは、サポート対象のブラウザ エンジンとは動作が異なり、カスタムのユーザー エージェントを使っているので、他では起きない違反が発生する可能性があります。それ以外にも、特定のブラウザでのみ発生する違反や、ナイトリー ビルドによる変更や新バージョンのブラウザによって発生する違反もあります。ユーザー エージェント情報がなければ、こういった違反を調査することは非常に困難になります。信頼できるユーザー : エンドポイントが違反の発生したドキュメントと same-site である場合、Reporting API がレポート エンドポイントに対して行うリクエストに利用可能な Cookie が添付されます。Cookie を取得すると、違反が起きたユーザーの種類を特定する際に役立ちます。対策すべき違反の多くは、会社の従業員やウェブサイト管理者など、信頼できるユーザーによるものであり、これらのユーザーが侵略的な拡張機能をインストールしたり、マルウェアに感染していたりすることはないでしょう。レポート エンドポイントから認証情報を取得できない場合は、まず信頼できるユーザーを対象に report-only ポリシーを設定してみましょう。そうすることで、対策すべき違反の基準を明確にしてから、ポリシーを一般公開することができます。ユニーク ユーザー数 : 一般原則として、典型的な機能やコードパスのユーザーからは、ほぼ同じ違反が生成されるといえます。そのため、少数のユーザーでしか発生していない違反は除外候補とすることができます。つまり、アプリケーションのコードではなく、ユーザーの特定の設定が問題である可能性があるということです。「ユーザー数をカウントする」方法の 1 つは、違反を報告したユニーク IP アドレス数を記録することです。近似カウント アルゴリズムは使いやすく、特定の IP アドレスを追跡せずにこの情報を収集できます。たとえば、HyperLogLog アルゴリズムは、わずか数バイトで、信頼度高く、集合内のおおまかな一意の要素数を数えることができます。
違反をソースコードにマッピングする(高度な内容)
違反のタイプによっては、source_file フィールドまたはそれと同等のフィールドが含まれます。このフィールドは、違反の原因となった JavaScript ファイルを表し、通常は行番号と列番号が付いています。これらの 3 ビットデータは高品質の信号であり、リファクタリングが必要なコードの行を直接指すことができます。
ただし、コンパイルや最小化のために、ブラウザがフェッチしたソースファイルがコードベースに直接マッピングできなくなることもよくあります。その場合は、JavaScript ソースマップを使って、デプロイされたファイルとオーサリングされたファイル の間で行番号と列番号をマッピングするとよいでしょう。すると、違反レポートがソースコードの行に直接変換されるので、非常に対策しやすいレポート グループと根本原因が生成されます。
独自のソリューションを確立する
Reporting API は、セキュリティ違反、非推奨の API 呼び出し、ブラウザの介入などのブラウザ側イベントを、イベントごとに指定されたエンドポイントに送信します。ただし、前のセクションで説明したように、そのレポートから実際の問題を抽出するには、データ処理システムが必要です。
幸いなことに、さまざまな方法で必要なアーキテクチャを設定できるようになっており、オープンソースのプロダクトもあります。必要なシステムの基本的な要素は次のとおりです。
API エンドポイント : HTTP リクエストを受け取り、JSON 形式でレポートを処理するウェブサーバーストレージ : 受け取ったレポートやパイプラインで処理したレポートを格納するストレージ サーバーデータ パイプライン : ノイズを除去し、必要なメタデータを抽出して集約するパイプラインデータ視覚化ツール : 処理したレポートから知見を得るためのツール
以上の各コンポーネントのソリューションは、パブリック クラウド プラットフォーム、SaaS サービス、オープンソース ソフトウェアとして利用できます。詳細については、
代替ソリューション のセクションをご覧ください。また、次のセクションでは、サンプル アプリケーションの概要を説明します。
サンプル アプリケーション : Reporting API プロセッサ
ブラウザからレポートを受け取る方法と、受け取ったレポートを処理する方法を理解できるように、小さなサンプル アプリケーション を作成しました。このアプリケーションで、ブラウザが送信したレポートからウェブ アプリケーションのセキュリティ問題を抽出するために必要なプロセスを示します。具体的には、以下のプロセスになります。
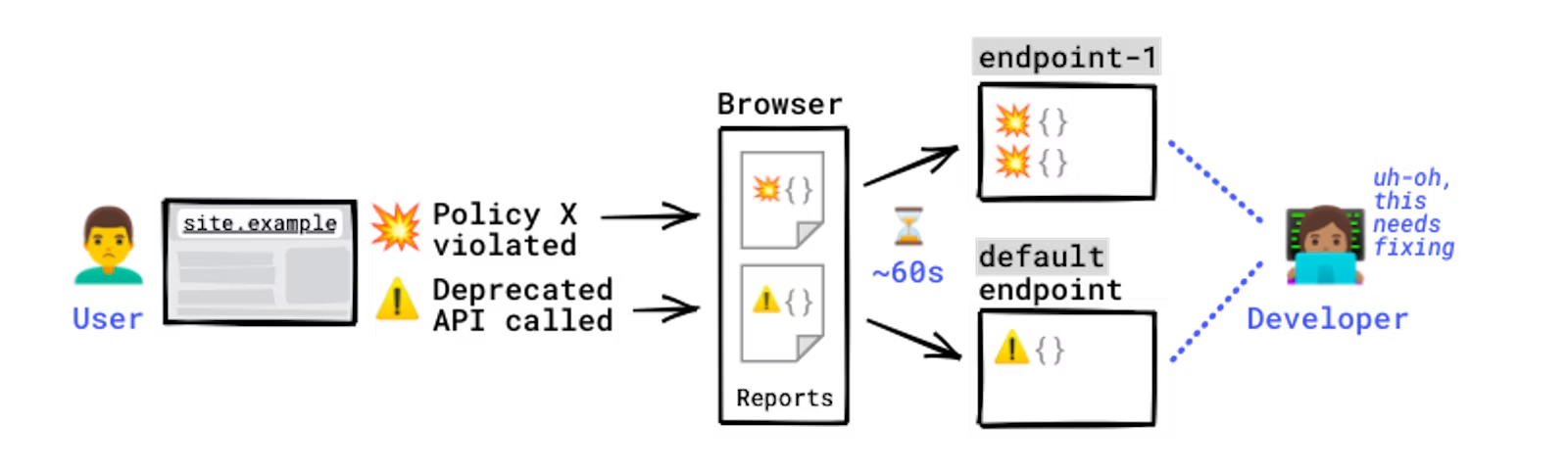
このサンプルでは、Google Cloud を使っていますが、各コンポーネントはお好みのテクノロジーに置き換えることができます。サンプル アプリケーションの概要を次の図に示します。
緑色のボックスは、独自に実装する必要があるコンポーネントです。 フォワーダ(forwarder) はシンプルなウェブサーバーであり、JSON 形式のレポートを受け取り、それを Bigtable 用のスキーマに変換します。 ビームコレクタ(beam-collector) はシンプルな Apache Beam パイプラインであり、ノイズの多いレポートをフィルタリングし、関連するレポートを集約して、CSV ファイルとして保存します。この 2 つのコンポーネントは、Reporting API からのレポートを有効利用するうえで重要な役割を果たしています。
実際に試す
これは実際に実行できるサンプル アプリケーションなので、すべてのコンポーネントを Google Cloud プロジェクトにデプロイし、自分で仕組みを確認することができます。サンプル システムを設定するための詳細な前提条件と手順は、
README.md ファイルに記載されています。
代替ソリューション
ここで共有したオープンソース ソリューション以外にも、Reporting API を簡単に使えるようにするツールがいくつも用意されています。次のようなものがあります。
Sentry や Datadog などのアプリケーション エラー モニタリング プラットフォーム
代替案を選択する際は、価格だけでなく、次の点を考慮するようにしましょう。
アプリケーションの URL をサードパーティのレポート収集ツールに渡しても構わないでしょうか?ブラウザが URL から機密情報を取り除いたとしても、機密情報はこのように漏洩する可能性 があります。アプリケーションにとってリスクが高すぎると思われる場合は、独自のレポート エンドポイントを運用してください。 収集ツールは、必要なすべてのレポートタイプをサポートしていますか?たとえば、すべてのレポート エンドポイント ソリューションが COOP/COEP 違反レポートをサポートしているわけではありません。
まとめ
この記事では、ウェブ デベロッパーが Reporting API を使ってクライアント側の問題を収集する方法と、収集したレポートから実際の問題を抽出する際の課題について説明しました。また、その課題を解決するために Google がどのようにレポートをフィルタリングして処理しているかを説明し、同様のソリューションを実現する際に利用できるオープンソース プロジェクトを紹介しました。この情報が役立ち、Reporting API を活用するデベロッパーが増え、結果としてウェブサイトの安全性と持続可能性が向上することを願っています。
学習リソース
Reviewed by
Eiji Kitamura - Developer Relations Team
日本時間 8 月 1 日(木)、2 日(金)に、旗艦イベント Google Cloud Next Tokyo '24 を開催します。待望のセッション情報が公開されました!
☁︎ 基調講演 生成 AI に関する革新的な取り組みを行う企業の取り組みや、Google Cloud の最新ソリューションをお届けします。DAY1 は、LINEヤフー、星野リゾートなどいち早く生成 AI を活用されている企業が登壇し、ビジネス変革のヒントをお届けします。DAY2 は、開発者目線で Google Cloud が提供する生成 AI のコンセプトや、日本テレビ、ヤマト運輸、トヨタ自動車、三井住友フィナンシャルグループなど、業界をリードする企業がいかに Google Cloud を活用しているか、語ります。
☁︎ おすすめセッション 以下に、一部ご紹介します。当日のライブ配信がないこと、また席数に限りがあるので、気になるものがあれば、イベント登録 をした後に、早めにセッション登録いただきますよう、お願いします。
【AI と機械学習】生成 AI Innovation Awards 最優秀賞!AI と人を共進化に導く学習業務活用支援
ソフトバンク Axross の学習の業務定着化支援機能での Vertex AI など Google Cloud をフル活用したアーキテクチャを紹介します。新機能である協働ノートでの学び、意見を Vertex AI 支援で発散 / 収束させ、組織独自のノウハウ ドキュメント化を促進、知識 / スキルを可視化 / 数値化します。それらデータ活用で人に合わせて支援 AI 自体が進化、AI と人が協調的に進化する AI 時代最適なプラットフォームの提案です。
【アプリケーション開発】サーバレスでモバイルアプリ開発! NTTコム「ビジネスdアプリ」のアーキテクチャ NTTコミュニケーションズが中小企業向けに開発したモバイルアプリ「ビジネスdアプリ」は社員内製によって開発しています。Google Cloud のサーバレス サービスを徹底的に活用することによって、開発チームはプログラム開発に集中でき、短期間で開発をすることができました。本セッションでは Google Cloud のサーバレス サービスの活用のコツと注意点を解説します。 【インフラストラクチャ】同時接続数 185 万人を支えたパルワールドのインフラ最前線 発売 1 か月で総プレイヤー数 2500 万人を記録したパルワールド。大ヒットの裏側で起きた数々のエピソードや危機的事態を乗り切ったノウハウについて紹介します。 【データ分析】楽天グループの大規模データ分析ツール「Rakuten Analytics」における BigQuery 活用 「Rakuten Analytics」は、楽天グループの膨大なアクセスログを集約し、アナリストやデータ サイエンティストがデータのポテンシャルを最大限に引き出せるように設計された分析プラットフォームです。BigQuery を活用することによってパフォーマンスが大きく改善され、社内のデータドリブンな文化の実現に大きく前進したストーリーについて解説します。 【生産性とコラボレーション】Gemini for Google Workspace 最新アップデート 進化し続ける Gemini for Google Workspace の最新アップデート情報をお届けいたします。業務部門において、どのように利用されているのか?導入におけるメリット、最新機能をご紹介いたします。
開催概要 名称 : Google Cloud Next Tokyo '24(略称 Next Tokyo '24)
日時 : 日本時間 2024 年 8 月 1 日(木) ~ 2 日(金)
会場 : パシフィコ横浜 ノース
対象 : 開発者から CEO まで、クラウド テクノロジーを使ったビジネス課題の解決を探求する、すべての方
- お問い合わせ -
Google Cloud Next Tokyo 運営事務局
E-mail: [email protected]
日本時間 8 月 1 日(木)、2 日(金)に、旗艦イベント Google Cloud Next Tokyo '24 を開催します。待望のセッション情報が公開されました!
☁︎ 基調講演 生成 AI に関する革新的な取り組みを行う企業の取り組みや、Google Cloud の最新ソリューションをお届けします。DAY1 は、LINEヤフー、星野リゾートなどいち早く生成 AI を活用されている企業が登壇し、ビジネス変革のヒントをお届けします。DAY2 は、開発者目線で Google Cloud が提供する生成 AI のコンセプトや、日本テレビ、ヤマト運輸、トヨタ自動車、三井住友フィナンシャルグループなど、業界をリードする企業がいかに Google Cloud を活用しているか、語ります。
☁︎ おすすめセッション 以下に、一部ご紹介します。当日のライブ配信がないこと、また席数に限りがあるので、気になるものがあれば、イベント登録 をした後に、早めにセッション登録いただきますよう、お願いします。
【AI と機械学習】生成 AI Innovation Awards 最優秀賞!AI と人を共進化に導く学習業務活用支援
ソフトバンク Axross の学習の業務定着化支援機能での Vertex AI など Google Cloud をフル活用したアーキテクチャを紹介します。新機能である協働ノートでの学び、意見を Vertex AI 支援で発散 / 収束させ、組織独自のノウハウ ドキュメント化を促進、知識 / スキルを可視化 / 数値化します。それらデータ活用で人に合わせて支援 AI 自体が進化、AI と人が協調的に進化する AI 時代最適なプラットフォームの提案です。
【アプリケーション開発】サーバレスでモバイルアプリ開発! NTTコム「ビジネスdアプリ」のアーキテクチャ NTTコミュニケーションズが中小企業向けに開発したモバイルアプリ「ビジネスdアプリ」は社員内製によって開発しています。Google Cloud のサーバレス サービスを徹底的に活用することによって、開発チームはプログラム開発に集中でき、短期間で開発をすることができました。本セッションでは Google Cloud のサーバレス サービスの活用のコツと注意点を解説します。 【インフラストラクチャ】同時接続数 185 万人を支えたパルワールドのインフラ最前線 発売 1 か月で総プレイヤー数 2500 万人を記録したパルワールド。大ヒットの裏側で起きた数々のエピソードや危機的事態を乗り切ったノウハウについて紹介します。 【データ分析】楽天グループの大規模データ分析ツール「Rakuten Analytics」における BigQuery 活用 「Rakuten Analytics」は、楽天グループの膨大なアクセスログを集約し、アナリストやデータ サイエンティストがデータのポテンシャルを最大限に引き出せるように設計された分析プラットフォームです。BigQuery を活用することによってパフォーマンスが大きく改善され、社内のデータドリブンな文化の実現に大きく前進したストーリーについて解説します。 【生産性とコラボレーション】Gemini for Google Workspace 最新アップデート 進化し続ける Gemini for Google Workspace の最新アップデート情報をお届けいたします。業務部門において、どのように利用されているのか?導入におけるメリット、最新機能をご紹介いたします。
開催概要 名称 : Google Cloud Next Tokyo '24(略称 Next Tokyo '24)
日時 : 日本時間 2024 年 8 月 1 日(木) ~ 2 日(金)
会場 : パシフィコ横浜 ノース
対象 : 開発者から CEO まで、クラウド テクノロジーを使ったビジネス課題の解決を探求する、すべての方
- お問い合わせ -
Google Cloud Next Tokyo 運営事務局
E-mail: gc-nexttokyo-info@google.com