Google のウェブ エンジニアとして、私は過去 5 年間、社内チームやお客様向けのスケールド システムを開発してきました。システムの中には、ウェブのフロントやバックエンドのコンポーネントが含まれていることもよくあります。
この投稿では、Google Cloud Platform(GCP)を使って開発したカスタムメイドの機械学習システムの話をしたいと思います。このブログを読んで、自分でも何かクールなウェブ アプリを構築したいと思ってもらえれば幸いです。
この話は、私がコンピュータのビジョンに関心を持ったところから始まります。私は長年、この分野に興味を持っていました。読者の皆さんの中には、望みどおりの結果を得るために最もシンプルなソリューションを探そうと努力していた私の個人的な実験に関する公開ポストを目にした方がいらっしゃるかもしれません。
私はシンプルであることが大好きなのですが、自分の手がけるプロジェクトが年を追うごとに複雑になるにつれ、特にその気持ちが大きくなりました。仲のいい友人が昔、私に「シンプルであることは複雑な芸術だ」と言ったのですが、この業界に 10 年在籍して本当にそのとおりだと感じています。
コンピュータ ビジョンに関する私の初期の実験において、動きを分離させようとしているところ
私のウェブ エンジニア兼コンピュータ サイエンティストとしての経歴は、2004 年に当時人気だった LAMP などを手がけたことから始まりました。その後 2011 年に Google に入社し、Google Cloud スタックに出会いました。つまり Google App Engine のことです。私は、スケーリングとディストリビューションを扱うシステムによって時間が大きく節約できることを知り、以来 App Engine に夢中になっています。
しかし、2011 年から時は流れ、最近私は TensorFlow を使ってウェブ ベースの機械学習システムを開発するプロジェクトに関わりました。ここで、私が開発に使った Google Cloud の新技術を一部紹介しましょう。
課題 : 長期間稼働しているタスクと短時間でクリティカルなタスクの両方に対し、ジョブの実行を保証するには?
TensorFlow を使って Google Compute Engine によるカスタム オブジェクトを認識しているところ
今年の初め頃、私は Google が開発したマシン インテリジェンス向けのオープンソース ソフトウェアである TensorFlow の使い方を学んでいました(試す価値のあるものですよ)。
初期デザインと課題
私のアプリケーションでディープ ニューラル ネットワークの一部を再トレーニングするには、平均 30 分程度かかっていました。長時間かかるジョブがある可能性を考えると、ユーザーに進捗状況を知らせるために、リアルタイムのステータス アップデートを提供したいと思いました。
また、すでにトレーニングが済んだクラシファイヤーを使って画像分析をする必要もありました。これにかかる時間は、1 つのジョブにつき 100 ミリ秒以下です。こうした短時間のジョブが、30 分かかるような長時間のジョブにさえぎられるようなことがあってはなりません。
この段階で、次のような問題が発生しました。
-
Compute Engine のオートスケーリング プールを需要に合わせて 10 インスタンスまで作ることができたものの、時間のかかるトレーニング タスクが 10 個リクエストされると、分類やファイルのアップロードといったタスクのためのインスタンスが残らない。
プロジェクトの予算が限られていたため、一度に起動できるインスタンスは 10 個までだった。
データベースの選択肢
このアプリケーションでは、さまざまな種類のワークロードをサポートする必要があったことに加え、永続的データが保管できなくてはなりませんでした。それができるデータベースは数多く、当然のことながら Google Cloud SQL もその 1 つです。ただ、この方法にはいくつか問題がありました。
時間がかかる : Cloud SQL を使うには、SQL データベースと統合できるようにすべての DB コードを自分で書き直さなくてはなりません。また、稼働するプロトタイプをできるだけ早く提供する必要がありました。
セキュリティ : Cloud SQL の統合には、Google Compute Engine のインスタンスがコア データベースに直接アクセスする必要がありましたが、私はコア データベースを見せたくありませんでした。
さまざまな種類のジョブ : 今は 2016 年ですから、きっとこんな問題を解決する何かがあるはずで、さまざまなジョブの種類に対応できるはずですよね?
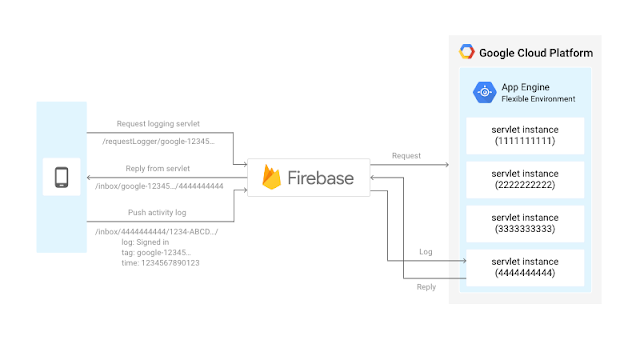
その解決策として私は、モバイル アプリケーションやウェブ アプリケーションの開発に向けた Google の Backend as a Service(BaaS)である Firebase を使うことにしました。
Firebase によって既存の API を使うことができ、(私の Node.js ベースのサーバーに最適な)JSON オブジェクトを使って永続的データを保管できるようになりました。これにより、クライアントが DB の変更をリッスンできるようになり(ジョブの進捗状況を伝えるのに最適です)、私の Cloud SQL のコア データベースと密接に統合する必要もなくなりました。
私が利用した GCP サービス
最終的に私はサーバーを 3 つのプールに分けました。それぞれのプールは特定のタスクに対して高度に特化させており、1 つは分類用、1 つはトレーニング用、そしてもう 1 つはファイルのアップロード用としました。各タスクで利用したクラウド技術は以下のとおりです。
Firebase
James Tamplin および彼のチームと話して以来、私はずっと Firebase をプロジェクトに使う機会をうかがっていました。
Firebase の主な機能の 1 つに、リアルタイム データベースを数分で作れるというものがあります。そう、リアルタイムです。しかも、JavaScript を使うだけで、更新のすべてをリッスンできるのです。Firebase を使えば、動くチャット アプリケーションが 5 分以内に作れます。
これは、リアルタイムでジョブの進捗状況を確認するのに最適です。というのも、私はフロントエンドに問題のあるジョブへの変更をリッスンさせ、GUI をリフレッシュできるためです。
また、すべてのウェブ ソケットや DB fun も処理されるので、私はすごく使いやすい API を使って JSON オブジェクトを渡すだけでいいのです。Firebase はオフラインにも対応しており、オンライン状態になった時点で同期されます。
Cloud Pub/Sub
Cloud Pub/Sub は、セントラル トピックにメッセージを送ることを可能にするもので、そこから Compute Engine インスタンスがサブスクリプションを作ることもできるし、セントラル トピックに対して非同期的に緩くつながった状態でプルやプッシュすることもできます。これにより、容量に空きが出ると、すべてのジョブが最終的に稼働することが保証されます。
また、これはすべて水面下で行われるため、自分でジョブをリトライする必要もありません。時間が大幅に節約できます。
 Cloud Pub/Sub のパブリッシャとなるエンドポイントの数に制限はなく、どこからでもサブスクリプションが可能
Cloud Pub/Sub のパブリッシャとなるエンドポイントの数に制限はなく、どこからでもサブスクリプションが可能
App Engine
私は App Engine でフロントエンド ウェブ アプリケーションをホストし、配信しました。HTML や CSS、JavaScript、テーマなどの資産はすべてここに保管されており、必要に応じて自動的にスケールされます。
さらにいい点は、App Engine がマネージド プラットフォームであることです。セキュリティ機能が搭載されているほか、App Engine の API に対して自分の好みの言語(Java、Python、PHP など)でコーディングした際に自動でスケーリングする機能も搭載されています。
API は Memcache や Cloud SQL などの高度な機能にもアクセスできるようになっており、負荷が増してもスケールする方法で頭を悩ませる必要はありません。
オートスケーリング機能の付いた Compute Engine
Compute Engine は、きっとほとんどのウェブ開発者になじみのあるものでしょう。これは、自分の選択した OS をインストールできるサーバーで、そのインスタンスに対して完全にルート アクセスすることが可能です。
インスタンスは完全にカスタマイズでき(仮想 CPU の数や、RAM、ストレージの容量も設定できます)、課金は分単位のため、要求に応じてスケールアップやスケールダウンする際にさらなるコスト削減が可能です。
もちろん、ルート アクセスができるということは、これらのマシンでやりたいと思っていたことがほぼ何でもできるということなので、私も TensorFlow を稼働させる環境としてこれを選びました。
また Compute Engine は、オートスケーリングのメリットも享受できます。要求に応じて、また設定した数値に応じて、利用できる Compute Engine インスタンスの数を増やしたり減らしたりすることが可能です。私のユースケースでは、CPU の平均利用率に応じてオートスケーラはいつも 2 から 10 のインスタンスとなっていました。
Cloud Storage
Google Cloud Storage は、(サイズ的にも数的にも)大量のファイルを安価に保管できるサービスです。世界中のエッジ サーバー ロケーションにレプリケーションされており、その場所は要求しているユーザーに近いロケーションとなっています。
私が自分の機械学習システムでクラシファイヤーをトレーニングするために使ったファイルをアップロードし、必要になるまで保管していたのもここです。
Network Load Balancer
私の JavaScript アプリケーションはウェブ カメラを利用していたので、安全な HTTPS 接続にてアクセスする必要がありました。Google の Network Load Balancer は、自分で定義した異なる Compute Engine クラスタにトラフィックを送ることができるものです。
私の場合、画像分類クラスタと、新しいクラシファイヤーをトレーニングするためのクラスタがあったので、何がリクエストされたかによって、そのリクエストを適切なバックエンドに HTTPS 経由ですべて安全に送ることができました。
すべてを組み合わせた結果
これらのコンポーネントをすべて組み合わせてみると、私のシステム アーキテクチャは、だいたい次のようなものになりました。
これでちゃんと動いてはいましたが、一部無駄な部分もありました。Google Compute Engine Upload Pool のコードは、単に App Engine 上で稼働するように Java で書き直せることに気づいたのです。こうすることで直接 Cloud Storage にプッシュできるため、Compute Engine インスタンスの余分なプールが必要なくなります。やった!
また、App Engine を使うことになったため、カスタムメイドの SSL ロード バランサも必要なくなりました。App Engine 単体で新しいジョブを Pub/Sub へと簡単に内部でプッシュでき、すべてのフロントエンドのアセットをそのまま appspot.com 経由で HTTPS にて送ることができるためです。
つまり、Google の appspot.com 上でデプロイした場合、最終的なアーキテクチャは次のようになるでしょう。
アーキテクチャの複雑さが軽減されるとメンテナンスも楽になり、コスト削減にもつながります。
まとめ
Pub/Sub と Firebase を使うことで、私は 1 週間以上の開発時間を削減できたと見ています。これで私は目の前の問題にすぐに取りかかり、短時間で解決できるようになりました。さらには、プロトタイプが要求に応じてスケールしていき、予算に余裕がまったくないときでもすべてのジョブを最終的に片付けられることを保証できるようになったのです。
Google Cloud Platform サービス群の組み合わせは、ウェブ開発者が完全なエンドツーエンド システムのプロトタイプを短時間で作るうえで素晴らしいツールキットであり、セキュリティと今後のスケーラビリティに対する支援も同時に得られるものです。ぜひ皆さんも試してみることをお勧めします。
- Posted by Jason Mayes, Google Web Engineer





 Cloud Pub/Sub のパブリッシャとなるエンドポイントの数に制限はなく、どこからでもサブスクリプションが可能
Cloud Pub/Sub のパブリッシャとなるエンドポイントの数に制限はなく、どこからでもサブスクリプションが可能